mysql数据表存储单表最大2000万?
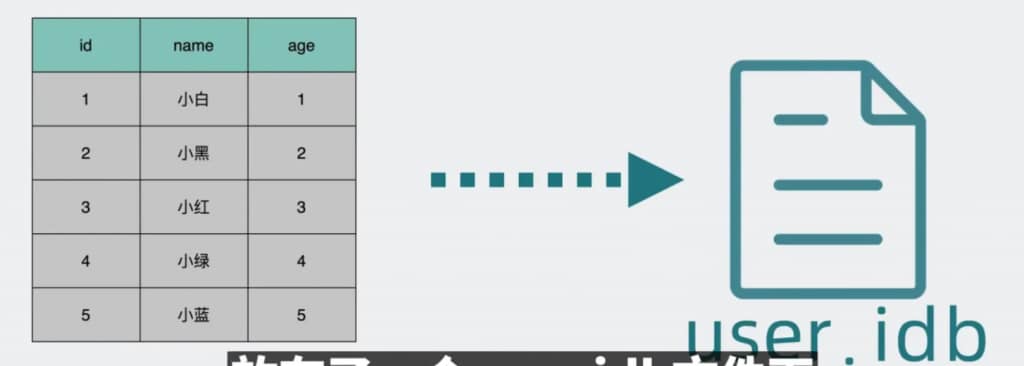
mysql的表数据在硬盘上也是放在一个xxx.ibd文件中
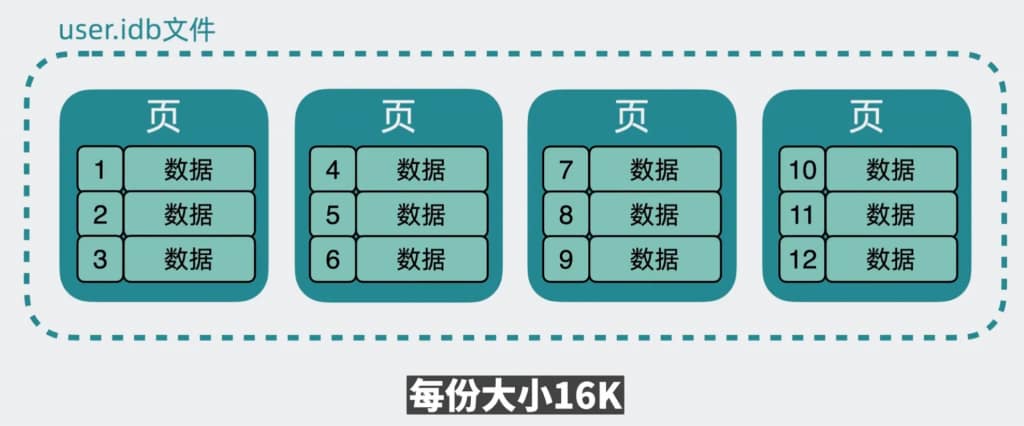
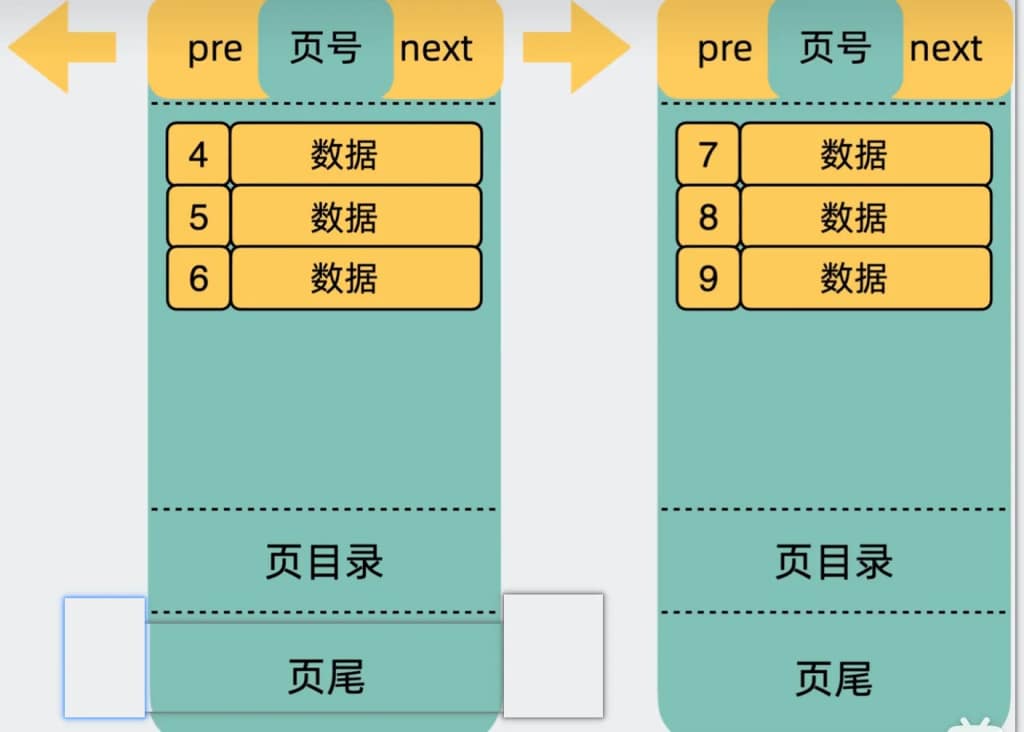
实际在user.ibd文件中,他们被分成多份小数据页。为了唯一标识是哪一页,我们需要引入页号的信息。同时,为了把这些数据页前后关联起来,引入了前后指针。用于指向前后的数据页。这些数据都被加入到了数据的页头中。
为了保证数据页的正确性。在页尾中加入了验证码。剩下的空间才是用来存放数据的。如果说这个页中的数据过多,查询遍历的时候可能会耗费很长时间,因此引入了页目录。
如果想查一条行数据。我们可以把表空间里的每一页都遍历出来进行查询。这样在数据量小的时候可以但是当数据量过大的时候性能就慢了。因为每次查找都有可能遍历所有的数据。
于是为了加速搜索,我们可以在每页数据中选出主键id最小行数据。而且只需要把主键id和所在页的页号,重新建立一个新页,这个新生成的数据页和之前的数据页没有什么大的区别,而且都是16K大小。同时为了和之前的数据页进行区分,这个数据页加入了页层级的信息。
于是数据页之间就有了上下级的关系。也就是B+树,最下层叫叶子节点。其他的都叫非叶子节点。我们创建的索引也会保存在非叶子节点中,叶子节点中存储的树数据表中的全部数据,因此数据表中常用的列可以建立索引,查询效率会很高
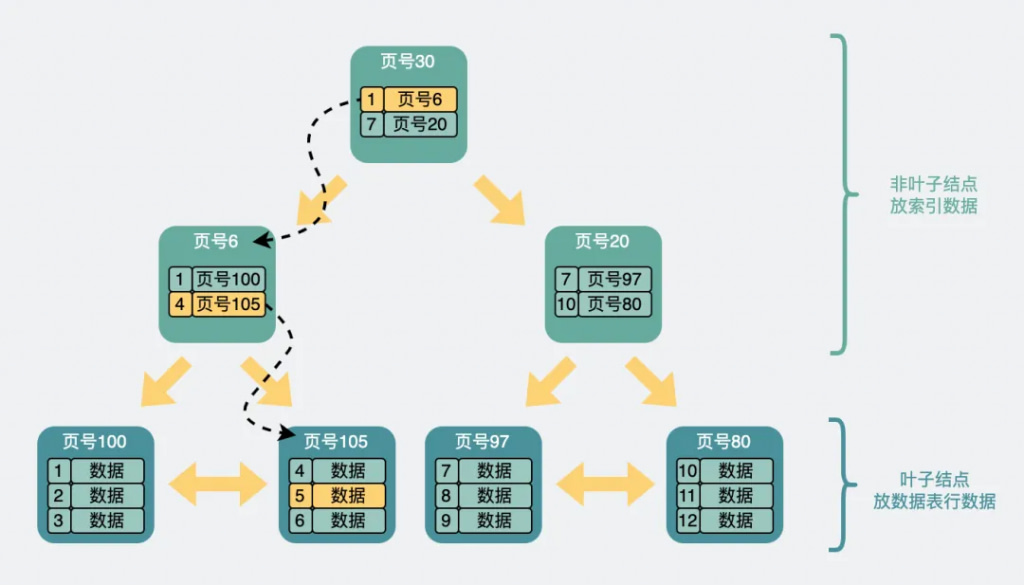
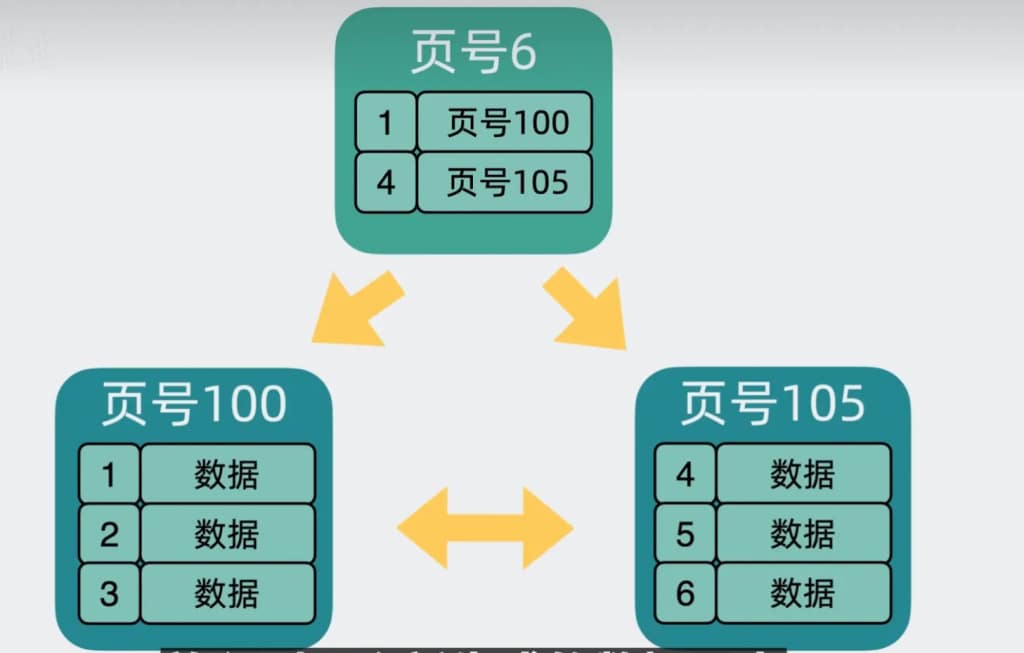
比方说我们想要查找行数据5。会先从顶层页的record们入手。record里包含了主键id和页号(页地址)。看下图黄色的箭头,向左最小id是1,向右最小id是7。那id=5的数据如果存在,那必定在左边箭头。于是顺着的record的页地址就到了6号数据页里,再判断id=5>4,所以肯定在右边的数据页里,于是加载105号数据页。在数据页里找到id=5的数据行,完成查询。
另外需要注意的是,上面的页的页号并不是连续的,它们在磁盘里也不一定是挨在一起的。
这个过程中查询了三个页,如果这三个页都在磁盘中(没有被提前加载到内存中),那么最多需要经历三次磁盘IO查询,它们才能被加载到内存中。
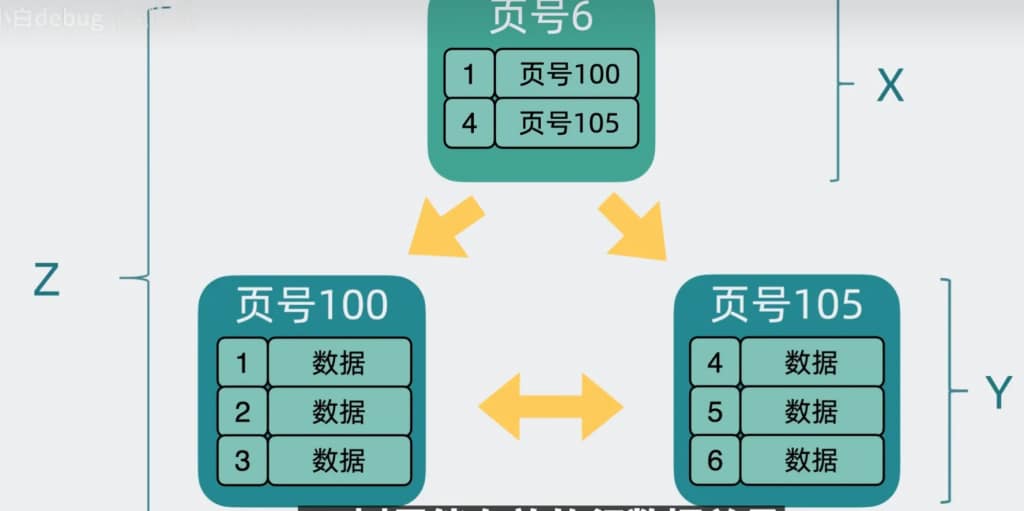
假设非叶子节点中指向其他页的数据量为X。叶子节点中存储的数据量为y。 B+树的层级为z
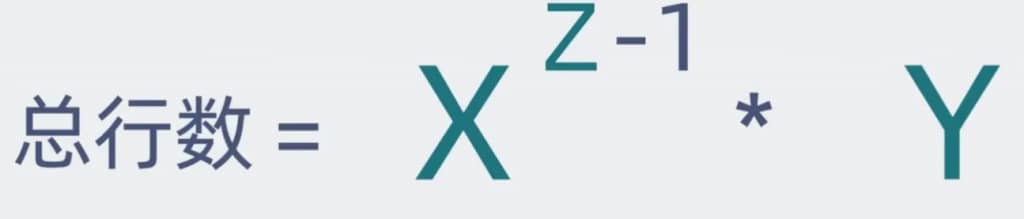
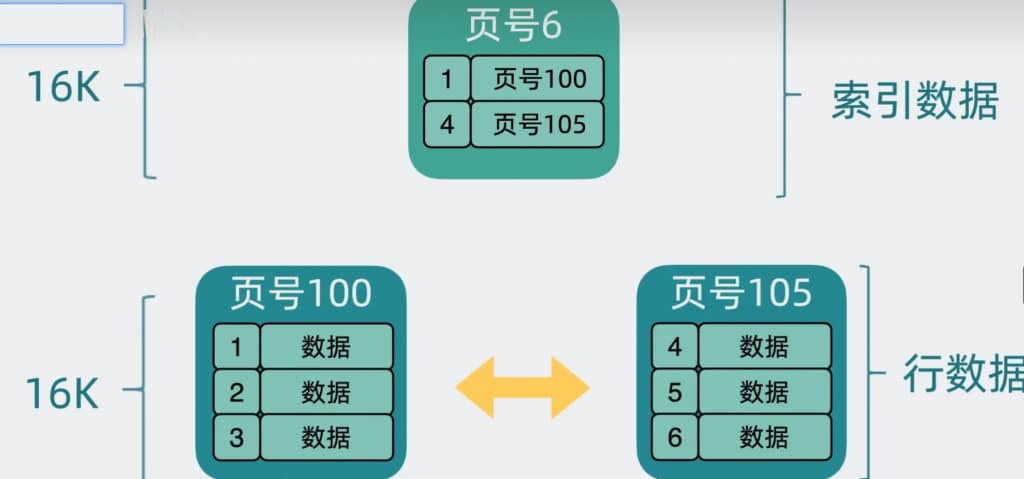
非叶子节点中。掐头去尾,可以有15K的大小存储数据。假如主键ID为bigint类型,为8字节,页号为4字节。那么一条数据就是12字节。用15K除以12字节等于 1280
在叶子节点中。掐头去尾,也剩15K左右。叶子节点中放入的是真正的行数据。假如每条数据我1kb大小。每一页数据可以存储15条数据。

这个二千五千万就是我们建议单表不超过两千万的由来。
0 条评论