六:Redis管道
对于基于 Request/Response 的服务器可以被实现成处理新的请求,即使客户端还没收到旧的响应。这样就可以同时发送多个命令给服务器而不用等待响应,最后统一读回多个返回。
这种方式被叫做 pipelining, 是一个广泛使用多年的技术,批量发送,批量返回。
一句话,批量命令处理变种优化措施,类似于reids的mget和mset
案列
[root@jwq1 myredis]# cat cat.txt
set k100 v100
set k200 v200
hset k300 name jj
hset k300 age 18
[root@jwq1 myredis]# cat cat.txt | /usr/local/bin/redis-cli -a 0000 --pipe
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 4
[root@jwq1 myredis]# 127.0.0.1:6379> keys *
1) "k200"
2) "k2"
3) "email"
4) "k300"
5) "k4"
6) "k1"
7) "k100"
127.0.0.1:6379> hget k300
(error) ERR wrong number of arguments for 'hget' command
127.0.0.1:6379> hgetall k300
1) "name"
2) "jj"
3) "age"
4) "18"
127.0.0.1:6379>
pipelining和原生批命令对吧
- 原生批命令是原子性的,pipelining是非原子性的
- 原生批命令只能执行一种命令,pipelining可以执行多少数据类型的命令
- 原生批命令是服务端实现,pipelining需要服务端和客户端共同实现
pipelining和事务对比
- 事务具有原子性,pipelining没有原子性
- 管道一次性将多条命令发送到服务端,事务是一条一条的发送,事务只有在执行exec命令后才执行,管道不会
- 执行事务是会阻塞其他命令,pipelining不会阻塞其他命令的执行
pipelining的注意事项
- pipelining缓冲的指令只会依次执行,不保证原子性,如果执行命令过程中发生异常,将会继续执行后续的指令
- pipelining组装的命令不能太多,否则可能长时间阻塞客户端,同时服务端也需要回复一个队列答复,占用很多内存
七:Redis发布订阅(了解)
SUBSCRIBE, UNSUBSCRIBE 和 PUBLISH 实现了 发布/订阅消息范例,发送者 (publishers) 不直接向特定的接收者发送消息 (subscribers),而是发布消息到频道(channel),不关心有没有订阅者。订阅者订阅关注一个或多个频道(channel),并且只接收他关注的消息,不管发布者是不是存在。发布者和订阅者的解耦提供了更大的伸缩性、更动态的网络拓扑。
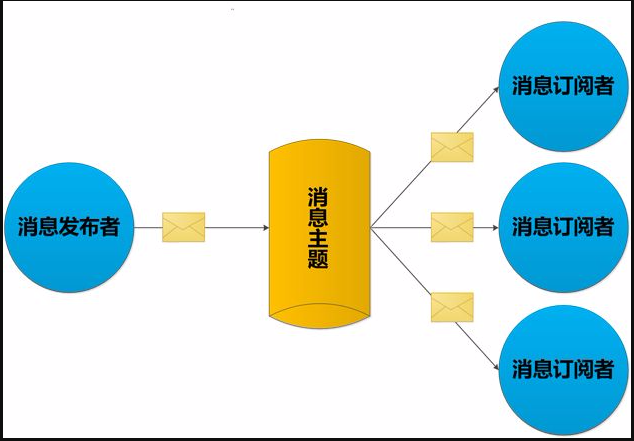
发布/订阅其实是一个轻量的队列,只不过数据不会被持久化,一般用来处理实时性较高的异步消息
八:Redis复制(replica)
在 Redis 复制的基础上,使用和配置主从复制非常简单,能使得从 Redis 服务器(下文称 slave)能精确得复制主 Redis 服务器(下文称 master)的内容。每次当 slave 和 master 之间的连接断开时, slave 会自动重连到 master 上,并且无论这期间 master 发生了什么, slave 都将尝试让自身成为 master 的精确副本。
这个系统的运行依靠三个主要的机制:
- 当一个 master 实例和一个 slave 实例连接正常时, master 会发送一连串的命令流来保持对 slave 的更新,以便于将自身数据集的改变复制给 slave , :包括客户端的写入、key 的过期或被逐出等等。
- 当 master 和 slave 之间的连接断开之后,因为网络问题、或者是主从意识到连接超时, slave 重新连接上 master 并会尝试进行部分重同步:这意味着它会尝试只获取在断开连接期间内丢失的命令流。
- 当无法进行部分重同步时, slave 会请求进行全量重同步。这会涉及到一个更复杂的过程,例如 master 需要创建所有数据的快照,将之发送给 slave ,之后在数据集更改时持续发送命令流到 slave 。
Redis使用默认的异步复制,其特点是低延迟和高性能,是绝大多数 Redis 用例的自然复制模式。但是,从 Redis 服务器会异步地确认其从主 Redis 服务器周期接收到的数据量。
主要能干吗呢?读写分离、容灾恢复、数据备份、水平扩容高并发
如何配置
配置文件固定写死
1.架构说明
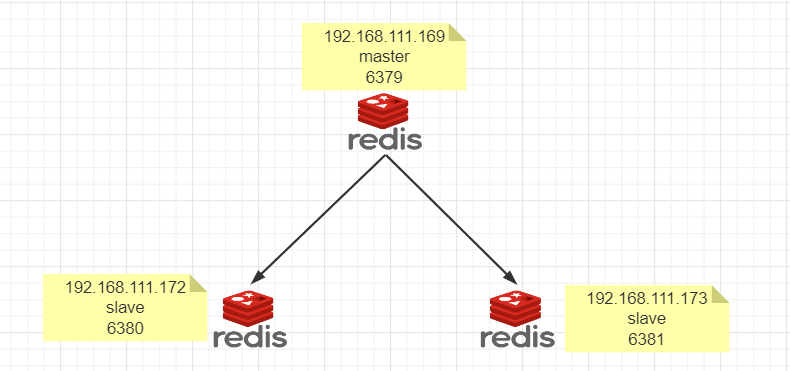
2.拷贝多个redis.conf 文件 redis6379.conf、redis6380.conf、redis6381.conf
修改配置文件细节
- 1.开启daemonize yes
- 2.注释掉bind 127.0.0.1
- 3.关闭受保护模式protected-mode no
- 4.指定端口port 6379
- 5.指定工作目录dir /myredis
- 6.pid 文件名称 pidfile /var/run/redis_6379.pid
- 7.log文件名称 logfile “/myredis/6379.log”
- 8.设置密码 requirepass 0000
- 9.dump.rdb文件名称 dbfilename dump6379.rdb
- 10.aof 文件
- appendonly yes
- appendfilename “appendonly6379.aof”
- 11.从机访问主机的通行密码,从机配置,主机不用配置
- masterauth “0000”
redis6380.conf、redis6381.conf做相对应的修改
3.从机配置文件redis6380.conf、redis6381.conf添加:
- replicaof 192.168.141.91 6379
- masterauth “0000”
先启动master后启动两台slave
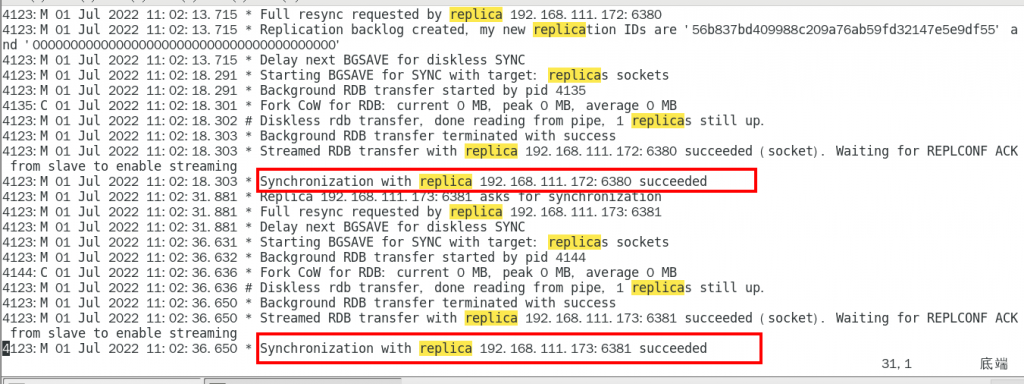
主机日志查看
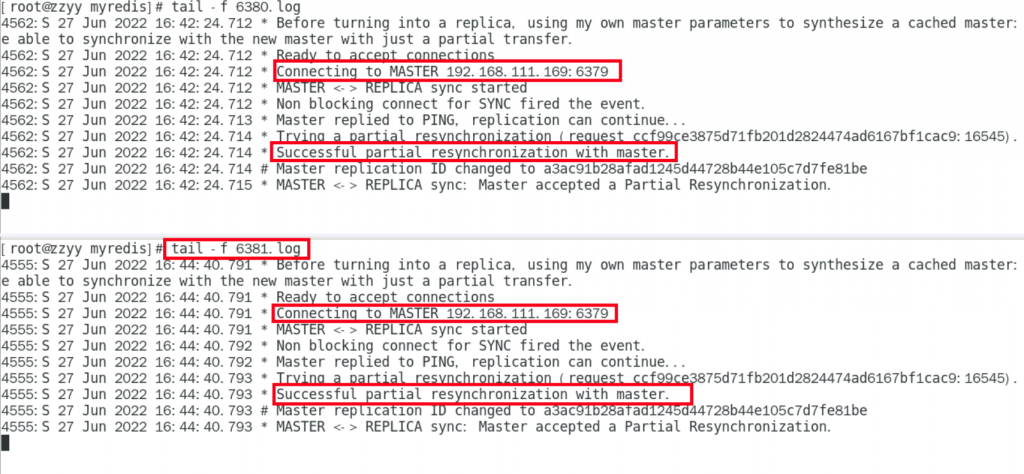
备机日志
命令查看:info replication
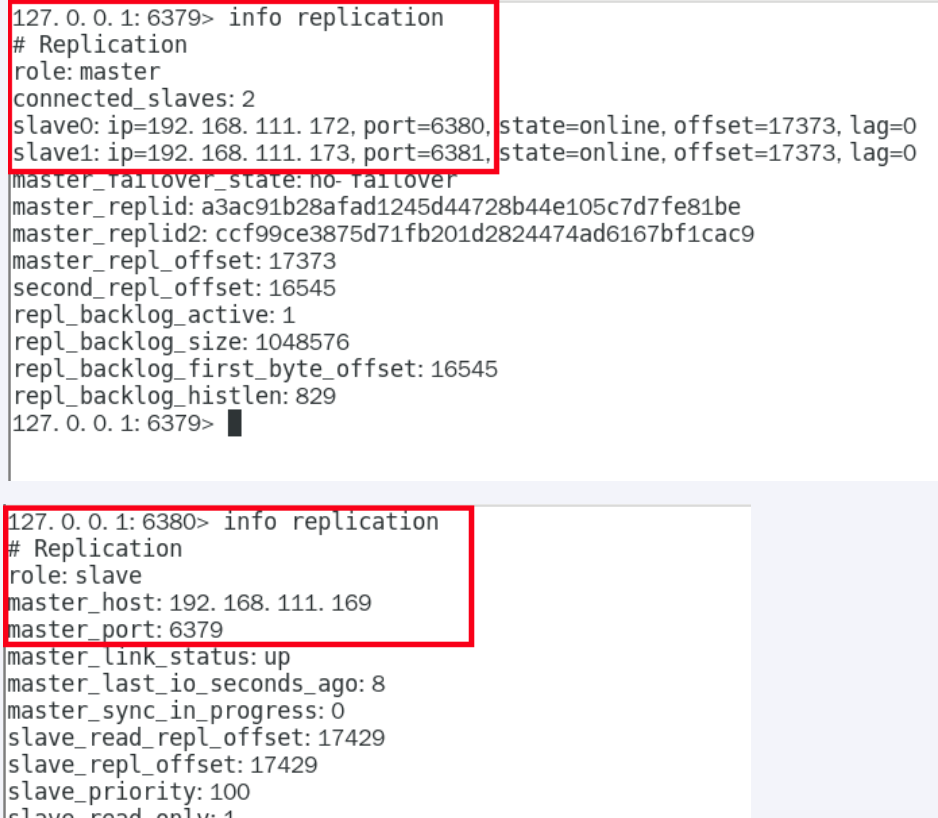
主从问题
- 1.从机可以执行命令吗? 不行
- 2.从机切入点问题?
- slave是从头开始复制还是从切入点开始复制?
master启动,写到k3
slave1跟着master同时启动,跟着写到k3
slave2写到k3后才启动,那之前的是否也可以复制?Y,首次一锅端,后续跟随,master写.slave跟
- slave是从头开始复制还是从切入点开始复制?
- 3.主机shutdown后,从机能上位吗?
- 从机不动,原地待命,从机数据可以正常使用;等待主机重启动归来
- 4.主机重新启动后,主从关系还在吗?从机还能顺利复制吗?
- 青山依旧在
- 5.从机down后,master继续,从机启动后还能继续跟上吗?
- 青山依旧在
命令操作指定主从关系
1.从机停机去掉配置文件中的配置项,3台redis都是master状态
2.从机上执行
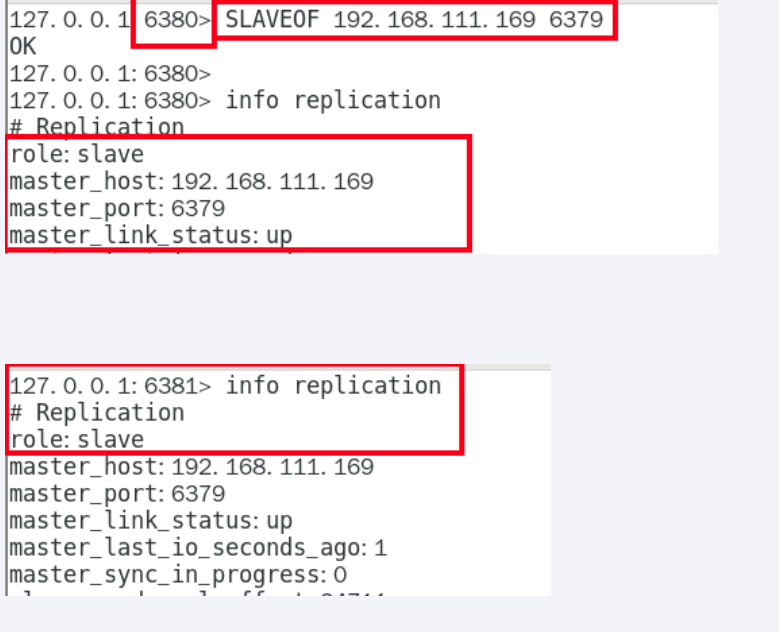
命令执行的话,从机重启后主从关系就不存在了
上面的这种配置是一主两从,还有薪火相传,上一个slave可以是下一个slave的master,slave同样可以接受其他的slaves的连接和同步,那么slave作为链条中的下一个master,可以有效减轻住master的写压力
反客为主:slaveof no one ,使当前数据库停止和其他数据库的同步,转为主数据库
复制原理和工作流程
- slave启动,同步初请,slave启动成功连接到master后会发送sync命令,一次完全同步(全量同步)默认被执行,slave自身的原有数据会被master覆盖
- 首次连接,全量复制,master节点首次接受到slave的同步命令后,会后台开始保存快照(RDB文件),同时收集所有接收到的用于修改数据的命令缓存起来,master执行rdb持久化完成后,master将快照和缓存的修改命令集发送给所有的slave,以完成一次全量同步
- 心跳持续,保持通讯,repl-ping-replica-period 10 ,master发出PING包的周期,默认是10秒
- 进入平稳,增量复制,master继续将新的所有收集的修改命令自动依次传递给slave,完成同步
- 从机下线,重连续传,master会检查backlog里面的offset,master和slave都会保存一个复制的offset和masterID,master只会把已经复制的offset后面的数据复制给slave,类似断点续传
Redis 复制功能是如何工作的
每一个 Redis master 都有一个 replication ID :这是一个较大的伪随机字符串,标记了一个给定的数据集。每个 master 也持有一个偏移量,master 将自己产生的复制流发送给 slave 时,发送多少个字节的数据,自身的偏移量就会增加多少,目的是当有新的操作修改自己的数据集时,它可以以此更新 slave 的状态。复制偏移量即使在没有一个 slave 连接到 master 时,也会自增,所以基本上每一对给定的
Replication ID, offset
都会标识一个 master 数据集的确切版本。
当 slave 连接到 master 时,它们使用 PSYNC 命令来发送它们记录的旧的 master replication ID 和它们至今为止处理的偏移量。通过这种方式, master 能够仅发送 slave 所需的增量部分。但是如果 master 的缓冲区中没有足够的命令积压缓冲记录,或者如果 slave 引用了不再知道的历史记录(replication ID),则会转而进行一个全量重同步:在这种情况下, slave 会得到一个完整的数据集副本,从头开始。
下面是一个全量同步的工作细节:
master 开启一个后台保存进程,以便于生产一个 RDB 文件。同时它开始缓冲所有从客户端接收到的新的写入命令。当后台保存完成时, master 将数据集文件传输给 slave, slave将之保存在磁盘上,然后加载文件到内存。再然后 master 会发送所有缓冲的命令发给 slave。这个过程以指令流的形式完成并且和 Redis 协议本身的格式相同。
你可以用 telnet 自己进行尝试。在服务器正在做一些工作的同时连接到 Redis 端口并发出 SYNC 命令。你将会看到一个批量传输,并且之后每一个 master 接收到的命令都将在 telnet 回话中被重新发出。事实上 SYNC 是一个旧协议,在新的 Redis 实例中已经不再被使用,但是其仍然向后兼容:但它不允许部分重同步,所以现在 PSYNC 被用来替代 SYNC。
之前说过,当主从之间的连接因为一些原因崩溃之后, slave 能够自动重连。如果 master 收到了多个 slave 要求同步的请求,它会执行一个单独的后台保存,以便于为多个 slave 服务。
无需磁盘参与的复制
正常情况下,一个全量重同步要求在磁盘上创建一个 RDB 文件,然后将它从磁盘加载进内存,然后 slave以此进行数据同步。
如果磁盘性能很低的话,这对 master 是一个压力很大的操作。Redis 2.8.18 是第一个支持无磁盘复制的版本。在此设置中,子进程直接发送 RDB 文件给 slave,无需使用磁盘作为中间储存介质。
复制的缺点
- 复制延迟,信号衰弱
- 由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
- master挂了,
- 默认情况下,不会在slave中重新选举出一个新的master,每次都要人工干预
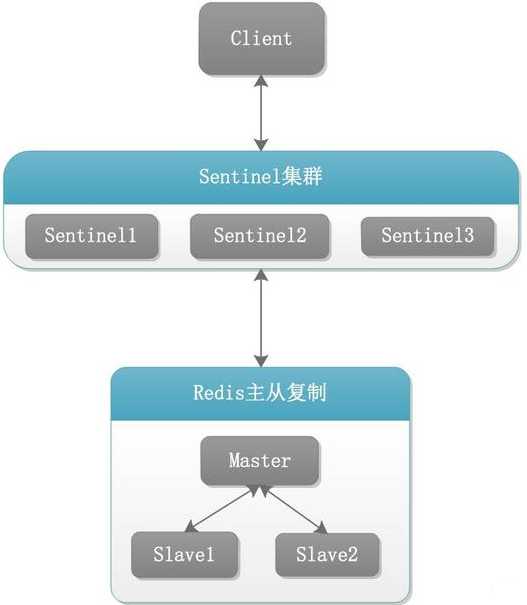
九:Redis哨兵(sentinel)
Redis Sentinel为Redis提供了高可用解决方案。实际上这意味着使用Sentinel可以部署一套Redis,在没有人为干预的情况下去应付各种各样的失败事件。
Redis Sentinel同时提供了一些其他的功能,例如:监控、通知、并为client提供配置。
下面是Sentinel的功能列表:
- 监控(Monitoring):Sentinel不断的去检查你的主从实例是否按照预期在工作。
- 通知(Notification):Sentinel可以通过一个api来通知系统管理员或者另外的应用程序,被监控的Redis实例有一些问题。
- 自动故障转移(Automatic failover):如果一个主节点没有按照预期工作,Sentinel会开始故障转移过程,把一个从节点提升为主节点,并重新配置其他的从节点使用新的主节点,使用Redis服务的应用程序在连接的时候也被通知新的地址。
- 配置提供者(Configuration provider):Sentinel给客户端的服务发现提供来源:对于一个给定的服务,客户端连接到Sentinels来寻找当前主节点的地址。当故障转移发生的时候,Sentinels将报告新的地址。
redis sentinel架构
如何配置
1.先看看/opt/redis-7.0.0 命令下的sentinel.conf
2.重点参数说明
- bind 服务监听地址,用于客户端连接,默认本地连接
- daemonize 是否以后台方式运行
- protected-mode 安全保护模式
- port 端口
- logfile 日志文件路径
- pidfile pid文件路径
- dir 工作目录
- sentinel monitor mymaster 127.0.0.1 6379 2 设置要监控的master服务器,2表示最少有几个哨兵认为客观下线,同意故障迁移
- sentinel auth-pass mymaster 0000 master设置了密码,连接master的密码
其他
- sentinel down-after-milliseconds <master-name> <milliseconds>:
- 指定多少毫秒之后,主节点没有应答哨兵,此时哨兵主观上认为主节点下线
- sentinel parallel-syncs <master-name> <nums>:
- 表示允许并行同步的slave个数,当Master挂了后,哨兵会选出新的Master,此时,剩余的slave会向新的master发起同步数据
- sentinel failover-timeout <master-name> <milliseconds>:
- 故障转移的超时时间,进行故障转移时,如果超过设置的毫秒,表示故障转移失败
- sentinel notification-script <master-name> <script-path> :
- 配置当某一事件发生时所需要执行的脚本
- sentinel client-reconfig-script <master-name> <script-path>:
- 客户端重新配置主节点参数脚本
3.我们三个哨兵同时部署在192.168.141.91同一台服务器上
sentinel26379.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26379
logfile "/myredis/sentinel26379.log"
pidfile /var/run/redis-sentinel26379.pid
dir /myredis
sentinel monitor mymaster 192.168.141.91 6379 2
sentinel auth-pass mymaster 111111sentinel26380.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26380
logfile "/myredis/sentinel26380.log"
pidfile /var/run/redis-sentinel26380.pid
dir "/myredis"
sentinel monitor mymaster 192.168.111.169 6379 2
sentinel auth-pass mymaster 111111sentinel26381.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26381
logfile "/myredis/sentinel26381.log"
pidfile /var/run/redis-sentinel26381.pid
dir "/myredis"
sentinel monitor mymaster 192.168.141.91 6379 2
sentinel auth-pass mymaster 1111114.一主两从3台redis实列,测试正常的主从复制
redis6379.conf、redis6380.conf、redis6381.conf
6379后续可能会变成从机,需要设置访问新主机的密码,请设置masterauth项访问密码为0000
5.再启动三个哨兵,完成监控
/usr/local/bin/redis-sentinel /myredis/sentinel26379.conf --sentinel
/usr/local/bin/redis-sentinel /myredis/sentinel26380.conf --sentinel
/usr/local/bin/redis-sentinel /myredis/sentinel26381.conf --sentinel
6.启动三个哨兵后,在查看主从复制:replication info
7.原有的master挂了,shutdown关闭6379,会从剩余的两台主机中,重新选举出一个master
会有一个问题,执行命令会出现Broken pipe

- 认识broken pipe
pipe是管道的意思,管道里面是数据流,通常是从文件或网络套接字读取的数据。当该管道从另一端突然关闭时,会发生数据突然中断,即是broken,对于socket来说,可能是网络被拔出或另一端的进程崩溃 - 解决问题
其实当该异常产生的时候,对于服务端来说,并没有多少影响。因为可能是某个客户端突然中止了进程导致了该错误 - 总结 Broken Pipe
这个异常是客户端读取超时关闭了连接,这时候服务器端再向客户端已经断开的连接写数据时就发生了broken pipe异常!
8. 6381被选举为新的master,上位成功;以前的6379重启后从master降级为slave;6380还是slave,只是换了master
9.配置文件的内容,在运行期间会被sentinel动态修改,master-slave切换后,master_redis.conf、slave_redis.conf、 sentinel.conf 的内容都会发生变动,即master_redis.conf中多了一行slaveof配置,sentinel.conf中的监控主机目标相对应变动
哨兵运行流程和选举原理
当一个主从配置中的master失效以后,sentinel可以选举出一个新的master,用于接替原有的master工作,主从配置中的其他slave自动指向新的master同步数据,一般建议sentinel采取奇数台,以防止某一台无法连接到master导致误切换
SDOWN主观下线
所谓主观下线(Subjectively Down, 简称 SDOWN)指的是
单个Sentinel实例对服务器做出的下线判断,即单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。主观下线就是说如果服务器在[sentinel down-after-milliseconds]给定的毫秒数之内没有回应PING命令或者返回一个错误消息, 那么这个Sentinel会主观的(单方面的)认为这个master不可以用了,o(╥﹏╥)o
sentinel down-after-milliseconds <masterName> <timeout>表示master被当前sentinel实例认定为失效的间隔时间,这个配置其实就是进行主观下线的一个依据
master在多长时间内一直没有给Sentine返回有效信息,则认定该master主观下线。也就是说如果多久没联系上redis-servevr,认为这个redis-server进入到失效(SDOWN)状态。
ODOWN客观下线
sentinel monitor <master-name> <ip> <redis-port> <quorum>masterName是对某个master+slave组合的一个区分标识(一套sentinel可以监听多组master+slave这样的组合)
quorum这个参数是进行客观下线的一个依据,法定人数/法定票数
意思是至少有quorum个sentinel认为这个master有故障才会对这个master进行下线以及故障转移。因为有的时候,某个sentinel节点可能因为自身网络原因导致无法连接master,而此时master并没有出现故障,所以这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用。
选举出领导者哨兵
当主节点被判段客观下线状态,各个哨兵节点会进行协商,也选举出一个领导者哨兵节点由该节点领导,进行故障迁移,采用Raft算法
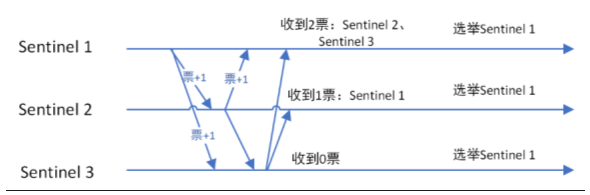
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:
即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者
领导者哨兵推动故障迁移选举新master
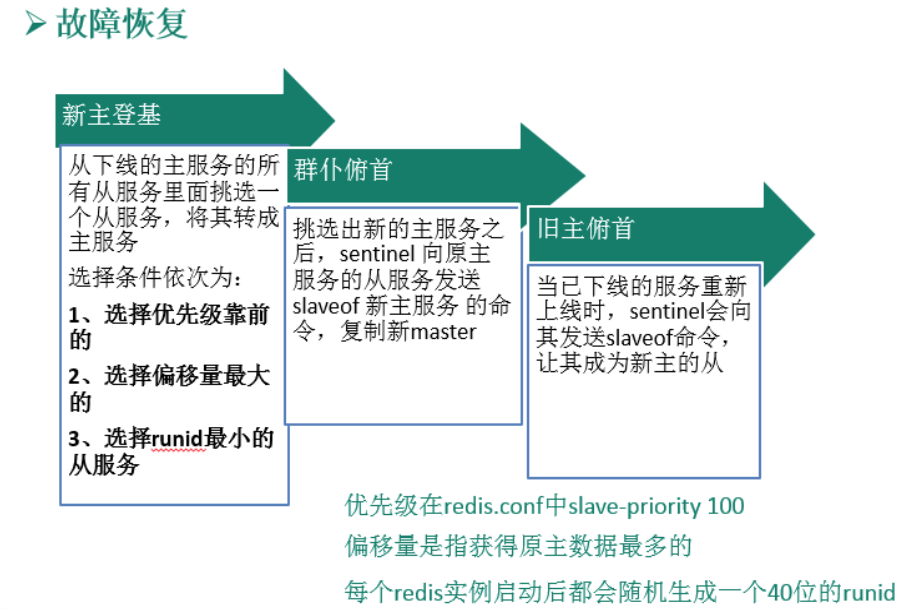
- 新主登基
- 某个slave被选举成新的master
- 选举出新master规则,前提是剩余的slave健康
- 与主节点断开的时间
- 从节点优先级
- 复制偏移处理最大的从节点
- 运行ID,字典顺序,ASCII码
- 群臣俯首
- 一朝天子一朝臣
- 执行slaveof no one 命令让新选举出来的slave升级为master,并通过slaveof命令让其他从节点成为其从节点
- 旧主拜服
- 老master回来也是从
- 将之前下线的master设置为新的master的从节点,当老master重新上线后,也会成为新master的从节点,sentinel leader会让原来的master降级为slave并恢复正常工作
- 以上操作均有sentinel哨兵自主完成,完全无需人工干预
Sentinels和从节点自动发现
Sentinels和其他的Sentinels保持连接为了互相之间检查是否可达和交换消息。然而你不需要在每个运行的Sentinel 实例中配置其他的Sentinel地址列表,Sentinel使用Redis实例的发布/订阅能力来发现其他的监控相同的主节点和从节点的Sentinels。
通过往名称为__sentinel__:hello的通道发送hello消息(hello messages)来实现这个特性。
同样的,你不需要配置一个主节点关联的从节点的列表,Sentinel也会自动发现这个列表通过问询Redis:
- 每隔两秒,每个Sentinel向每个监控的主节点和从节点的发布/订阅通道__sentinel__:hello来公布一个消息,宣布它自己的IP,端口,id。
- 每个Sentinel都订阅每个主节点和从节点的发布/订阅通道__sentinel__:hello,寻找未知的sentinels。当新的sentinels被检测到,他们增加这个主节点的sentinels。
- Hello消息也包含主节点的全部配置信息,如果接收的Sentinel有一个更旧的配置,它会立即更新它的配置。
- 在增加一个主节点的新的sentinel之前,Sentinel总是要检查是否已经有一个有相同的id、地址的sentinel。在这种情况下,所有匹配的sentinels被移除,新的被增加。
使用建议
- 哨兵节点的数量应该为多个,哨兵本身应该集群,保证高可用
- 哨兵节点的数量应该为奇数
- 各个哨兵节点的配置应该一致
- 如果节点部署在docker中,应该注意端口映射
- 哨兵集群+主从复制,并不能保证数据零丢失
十:Redis集群(cluster)
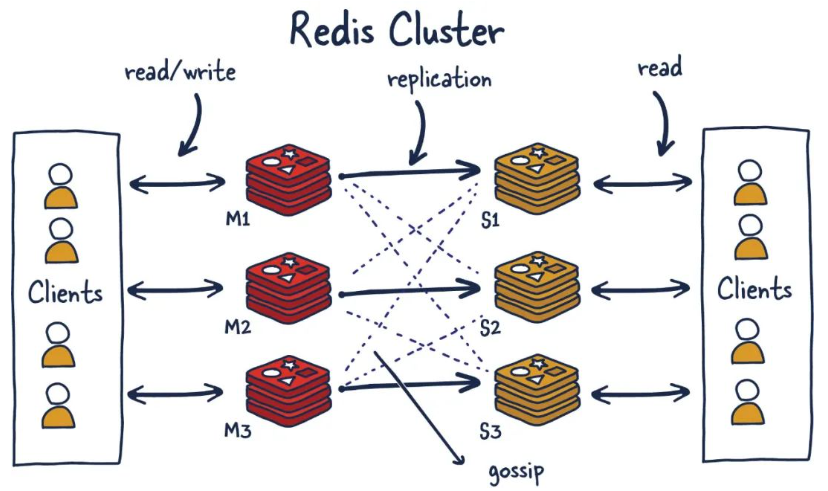
Redis Cluster 提供一种Redis安装方式:数据自动在多个Redis节点间分片。
Redis Cluster 提供一定程度的高可用,在实际的环境中当某些节点失败或者不能通讯的情况下能够继续提供服务。大量节点失败的情况下集群也会停止服务(例如大多数主节点不可用)。
Redis集群提供的能力:
- 自动切分数据集到多个节点上。
- 当部分节点故障或不可达的情况下继续提供服务。
主要干嘛
- redis集群支持多个master,而每个master又可以挂在多个slave
- 读写分离
- 支持数据高可用
- 支持海量数据的读写存储
- 由于集群自带故障迁移,内置了高可用模块,无需使用哨兵功能
- 客户端和redis节点连接,无需连接所有的节点,只需要连接集群中的任意一个可用节点即可
- 槽位slot负责分配到各个物理节点,对应的集群负责维护槽位、节点和数据之间的关系
Redis 集群和数据分片
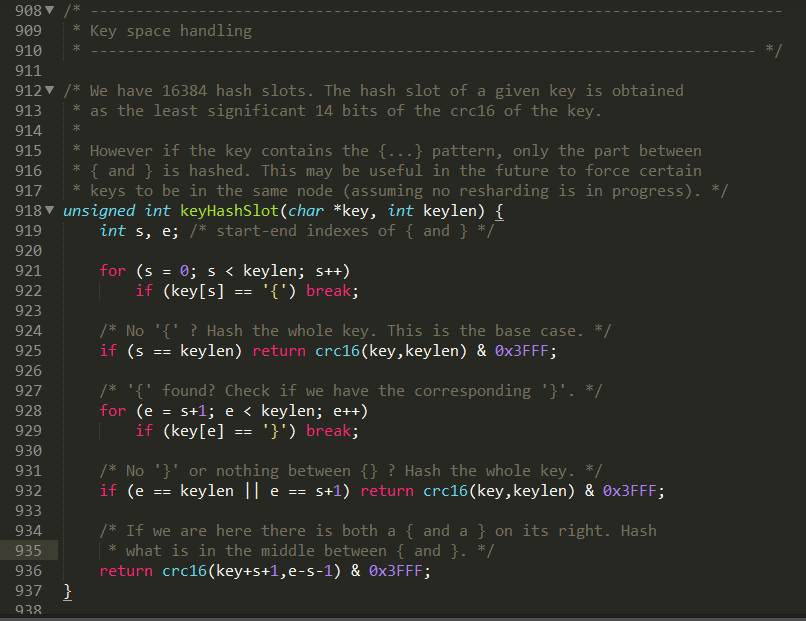
Redis集群不是使用一致性哈希,而是使用哈希槽。整个redis集群有16384个哈希槽,决定一个key应该分配到那个槽的算法是:计算该key的CRC16结果再模16834。
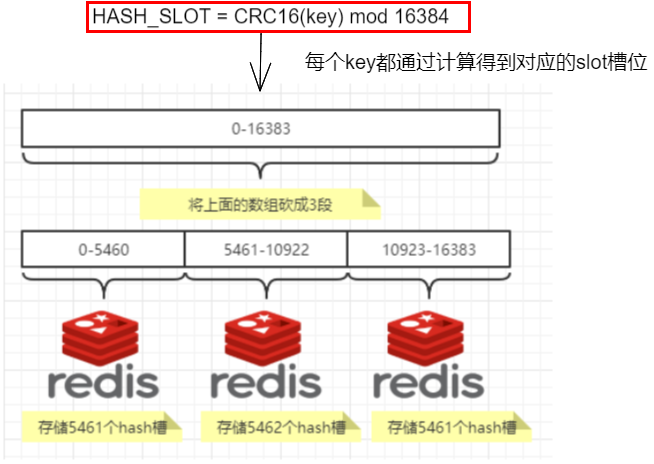
集群中的每个节点负责一部分哈希槽,比如集群中有3个节点,则:
- 节点A存储的哈希槽范围是:0 — 5500
- 节点B存储的哈希槽范围是:5501 — 11000
- 节点C存储的哈希槽范围是:11001 — 16384
使用Redis集群时我们会将存储的数据分散到多台redis机器上,这称为分片。简言之,集群中的每个Redis实例都被认为是整个数据的一个分片。为了找到给定key的分片,我们对key进行CRC16(key)算法处理并过对总分片数量取模。然后,使用确定性哈希函数,这意味着给定的key将多次始终映射到同一个分片,我们可以推断将来读取特定key的位置。
这样的分布方式方便节点的添加和删除。比如,需要新增一个节点D,只需要把A、B、C中的部分哈希槽数据移到D节点。同样,如果希望在集群中删除A节点,只需要把A节点的哈希槽的数据移到B和C节点,当A节点的数据全部被移走后,A节点就可以完全从集群中删除。
因为把哈希槽从一个节点移到另一个节点是不需要停机的,所以,增加或删除节点,或更改节点上的哈希槽,也是不需要停机的。
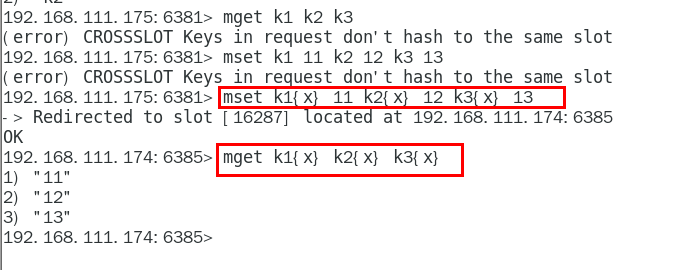
集群支持通过一个命令(或事务, 或lua脚本)同时操作多个key。通过”哈希标签”的概念,用户可以让多个key分配到同一个哈希槽。哈希标签在集群详细文档中有描述,这里做个简单介绍:如果key含有大括号”{}”,则只有大括号中的字符串会参与哈希,比如”this{foo}”和”another{foo}”这2个key会分配到同一个哈希槽,所以可以在一个命令中同时操作他们。
为什么redis集群最大槽数16384个?
CRC16算法产生的hash值有16bit,该算法可以产生2^16=65536个值。换句话说值是分布在0~65535之间,有更大的65536不用为什么只用16384就够?
| 正常的心跳数据包带有节点的完整配置,可以用幂等方式用旧的节点替换旧节点,以便更新旧的配置。这意味着它们包含原始节点的插槽配置,该节点使用2k的空间和16k的插槽,但是会使用8k的空间(使用65k的插槽)。同时,由于其他设计折衷,Redis集群不太可能扩展到1000个以上的主节点。因此16k处于正确的范围内,以确保每个主机具有足够的插槽,最多可容纳1000个矩阵,但数量足够少,可以轻松地将插槽配置作为原始位图传播。请注意,在小型群集中,位图将难以压缩,因为当N较小时,位图将设置的slot / N位占设置位的很大百分比。 |
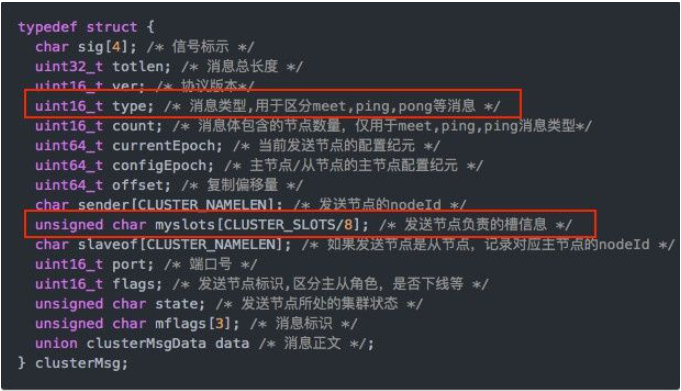
(1)如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为65536时,这块的大小是: 65536÷8÷1024=8kb
在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为16384时,这块的大小是: 16384÷8÷1024=2kb
因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
(2)redis的集群主节点数量基本不可能超过1000个。
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
(3)槽位越小,节点少的情况下,压缩比高,容易传输
Redis主节点的配置信息中它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
Redis 集群主从模式
为了保证在部分节点故障或网络不通时集群依然能正常工作,集群使用了主从模型,每个哈希槽有一(主节点)到N个副本(N-1个从节点)。
在我们刚才的集群例子中,有A,B,C三个节点,如果B节点故障集群就不能正常工作了,因为B节点中的哈希槽数据5501-11000没法操作。
但是,如果我们给每一个节点都增加一个从节点,就变成了:A,B,C三个节点是主节点,A1, B1, C1 分别是他们的从节点,当B节点宕机时,我们的集群也能正常运作。
B1节点是B节点的副本,如果B节点故障,集群会提升B1为主节点,从而让集群继续正常工作。但是,如果B和B1同时故障,集群就不能继续工作了。
配置步骤
1. 3主3从集群配置
1.找三台虚拟机,各自新建,因为机器原因,我就在一台机器上启动6个端口测试
mkdir /myredis/clusterrediscluster6381.conf、rediscluster6382.conf…..rediscluster6386.conf创建6个文件
rediscluster6381.conf内容
bind 0.0.0.0
daemonize yes
protected-mode no
port 6381
logfile "/myredis/cluster/cluster6381.log"
pidfile /myredis/cluster6381.pid
dir /myredis/cluster
dbfilename dump6381.rdb
appendonly yes
appendfilename "appendonly6381.aof"
requirepass 111111
masterauth 111111
cluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 5000。。。。。。。。。。82、83、84、85内容相同,改一下相对应的端口等
rediscluster6386.conf内容
bind 0.0.0.0
daemonize yes
protected-mode no
port 6386
logfile "/myredis/cluster/cluster6386.log"
pidfile /myredis/cluster6386.pid
dir /myredis/cluster
dbfilename dump6386.rdb
appendonly yes
appendfilename "appendonly6386.aof"
requirepass 111111
masterauth 111111
cluster-enabled yes
cluster-config-file nodes-6386.conf
cluster-node-timeout 50002.启动6台redis主机
[root@jwq1 cluster]# vim rediscluster6381.conf
[root@jwq1 cluster]# /usr/local/bin/redis-server /myredis/cluster/rediscluster6381.conf
[root@jwq1 cluster]# ps -ef | grep redis
root 3556 1 0 10:03 ? 00:00:00 /usr/local/bin/redis-server 0.0.0.0:6381 [cluster]
root 3565 1912 0 10:03 pts/1 00:00:00 grep --color=auto redis
[root@jwq1 cluster]# /usr/local/bin/redis-server /myredis/cluster/rediscluster6382.conf
[root@jwq1 cluster]# /usr/local/bin/redis-server /myredis/cluster/rediscluster6383.conf
[root@jwq1 cluster]# /usr/local/bin/redis-server /myredis/cluster/rediscluster6384.conf
[root@jwq1 cluster]# /usr/local/bin/redis-server /myredis/cluster/rediscluster6385.conf
[root@jwq1 cluster]# /usr/local/bin/redis-server /myredis/cluster/rediscluster6386.conf
[root@jwq1 cluster]# ps -ef | grep redis
root 3556 1 0 10:03 ? 00:00:00 /usr/local/bin/redis-server 0.0.0.0:6381 [cluster]
root 3568 1 0 10:04 ? 00:00:00 /usr/local/bin/redis-server 0.0.0.0:6382 [cluster]
root 3573 1 0 10:04 ? 00:00:00 /usr/local/bin/redis-server 0.0.0.0:6383 [cluster]
root 3579 1 0 10:04 ? 00:00:00 /usr/local/bin/redis-server 0.0.0.0:6384 [cluster]
root 3584 1 0 10:04 ? 00:00:00 /usr/local/bin/redis-server 0.0.0.0:6385 [cluster]
root 3591 1 0 10:04 ? 00:00:00 /usr/local/bin/redis-server 0.0.0.0:6386 [cluster]
root 3601 1912 0 10:04 pts/1 00:00:00 grep --color=auto redis
[root@jwq1 cluster]#
3.通过redis-cli命令构建集群关系
redis-cli -a 111111 --cluster create --cluster-replicas 1 192.168.111.175:6381 192.168.111.175:6382 192.168.111.172:6383 192.168.111.172:6384 192.168.111.174:6385 192.168.111.174:6386–cluster-replicas 1 表示为每个master创建一个slave节点
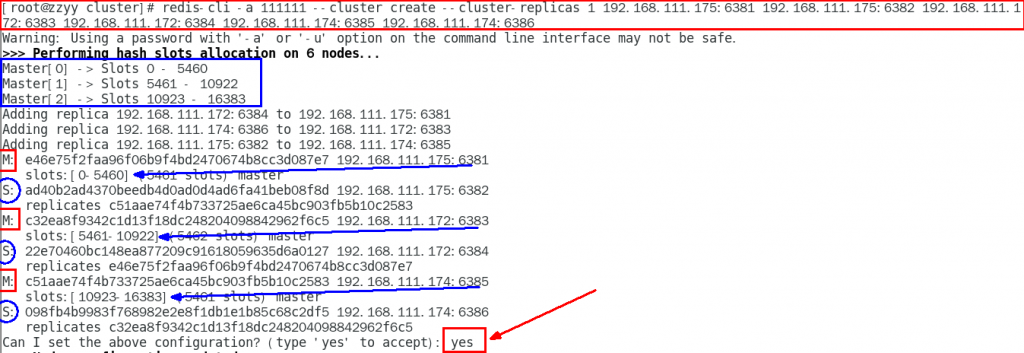
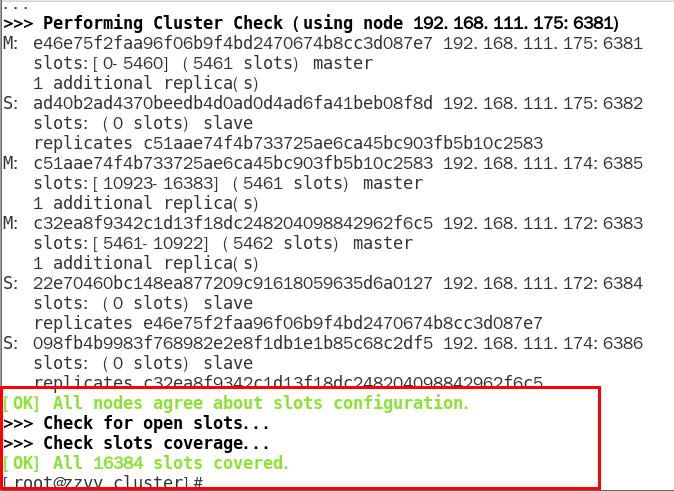
进入6381,检查集群状态
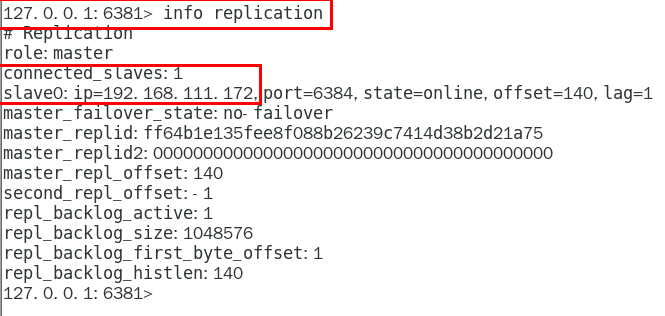
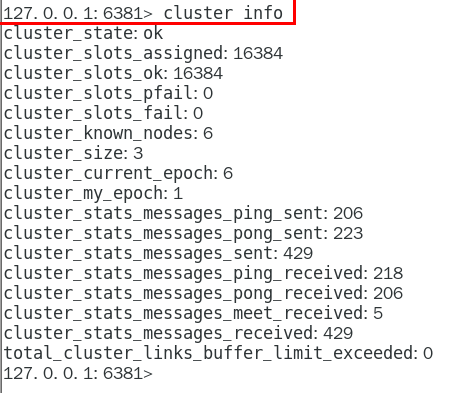

其他的一些命令查看集群状态:
redis-cli -h <节点IP> -p <端口> cluster info
redis-cli -h <节点IP> -p <端口> cluster nodes2. 3主3从集群读写
对6381新增2个key
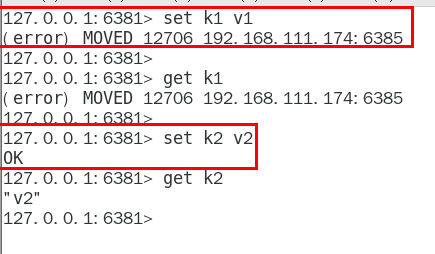
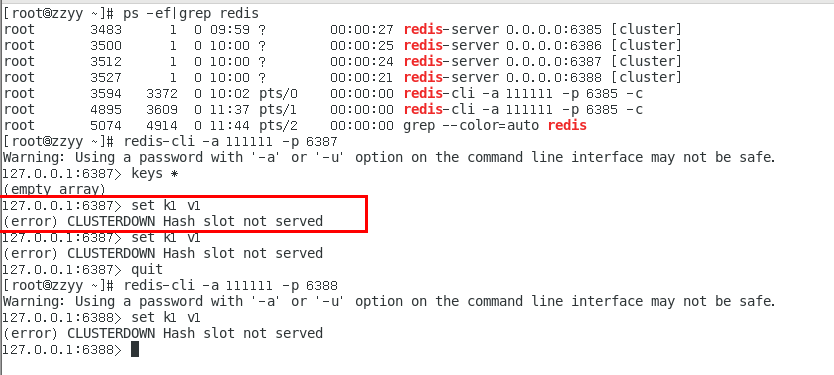
报错,一定注意槽位的范围区间,需要路由到位,路由到位,路由到位,路由到位

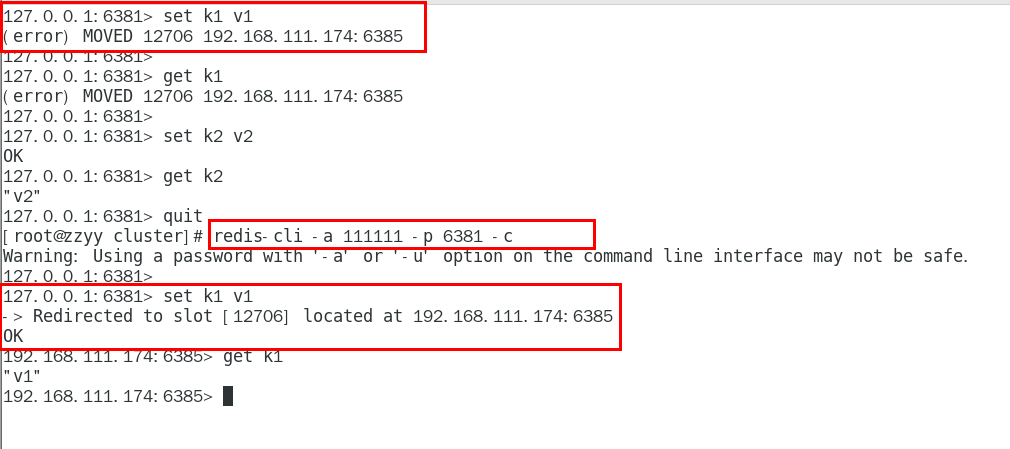
加入参数-c,优化路由
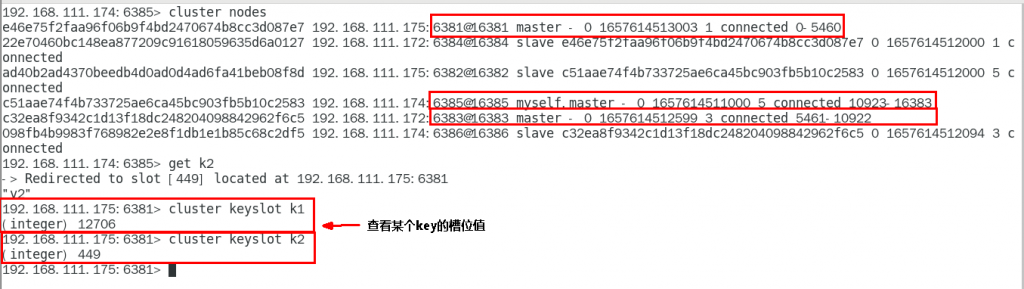
查看某个键对应的槽位
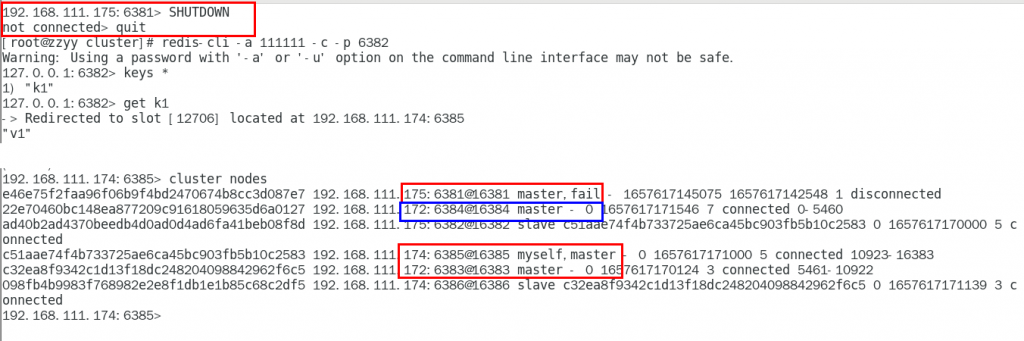
3. 主从容错切换迁移
1.主6381和从机切换,先停止主机6381,对应的从机上位,集群为6381 分配的从机以实际情况为准
此次6381主6384从

6381停机,再次查看集群信息,6384上位成为新的master
6381恢复连接,不会上位,以从节点形式回来
恢复前

恢复后
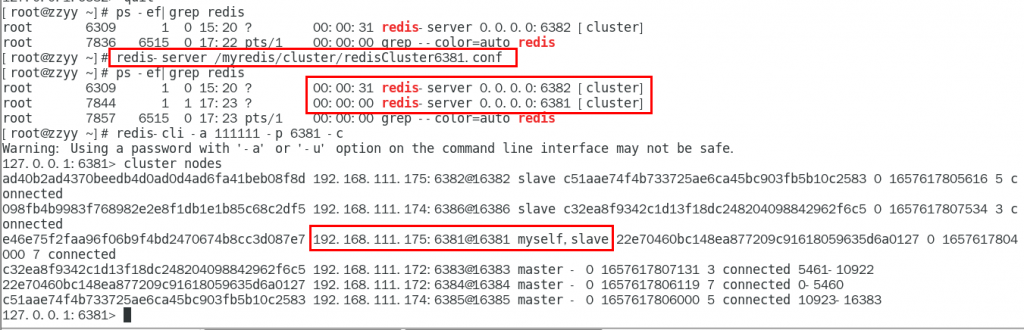
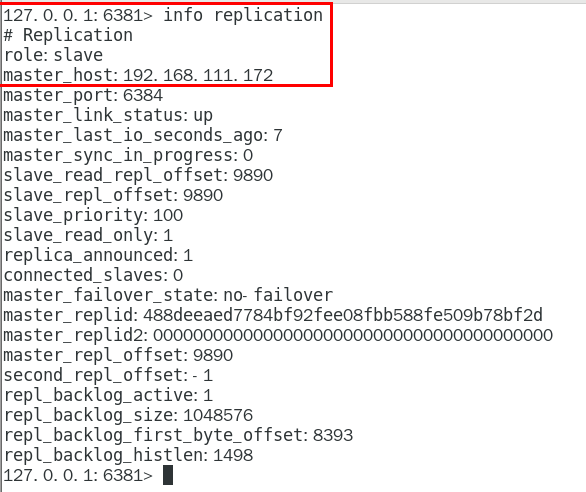
集群不保证数据100%ok,一定会有数据丢失的情况,这意味者在特定的情况下,reids集群可能会丢失一些被系统收到的写入请求命令
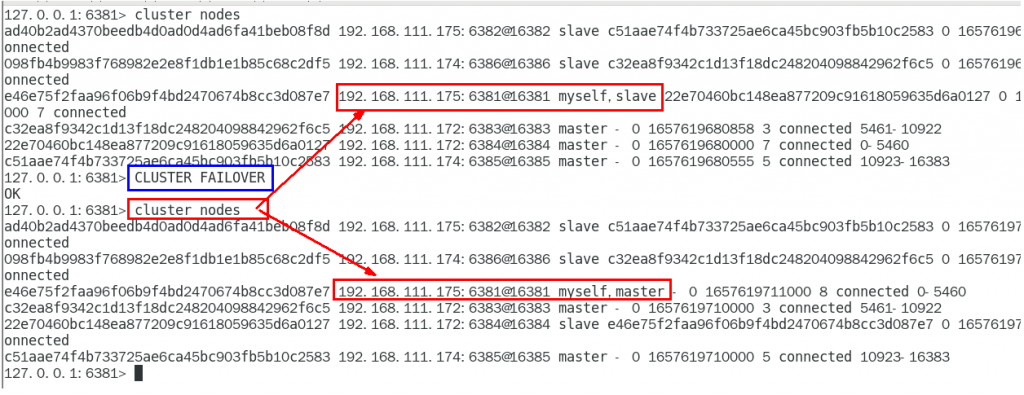
手动故障迁移,节点从属关系调整,上面一换后主从关系调换了,登录从节点6381,执行 cluster failover
4.主从扩容案列
1.新增6387 6388两个服务实列配置文件,并启动服务,内容和其他配置文件一致,注意端口、日志等修改即可
2.启动服务,他们都是master
3. 将新增的6387作为master节点加入原有集群
redis-cli -a 密码 –cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381
6387 就是将要作为master新增节点
6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
redis-cli -a 0000 --cluster add-node 192.168.111.174:6387 192.168.111.175:6381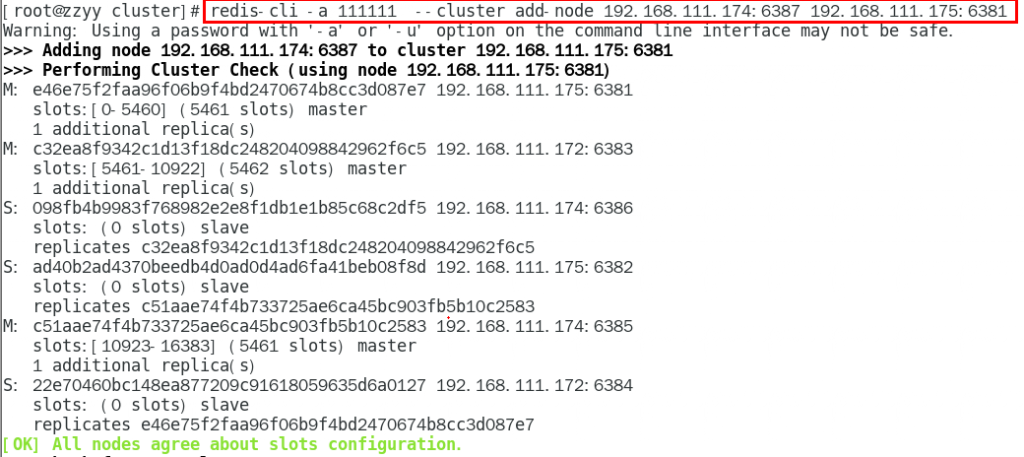
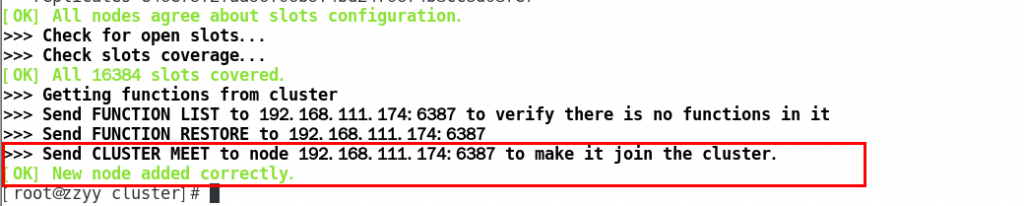
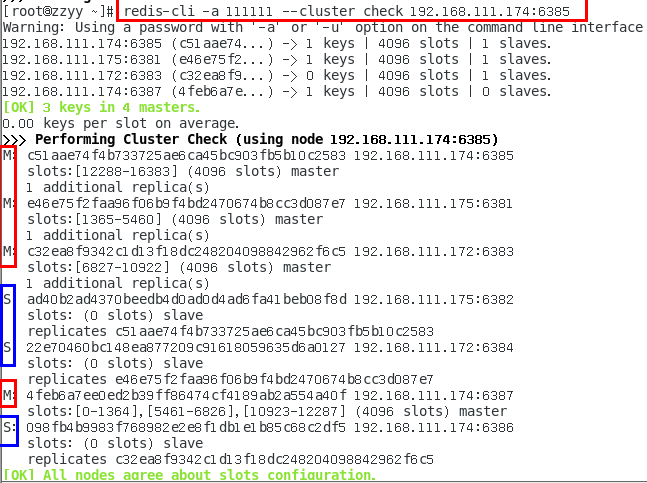
4.检查集群状态
redis-cli -a 111111 --cluster check 192.168.111.175:6381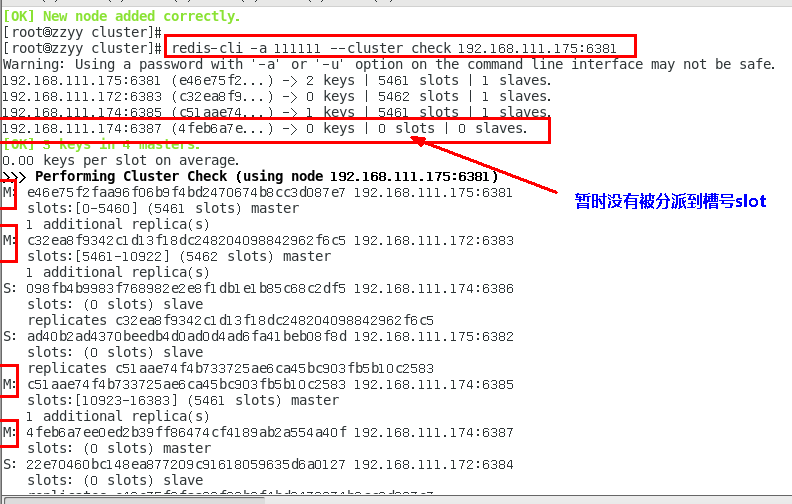
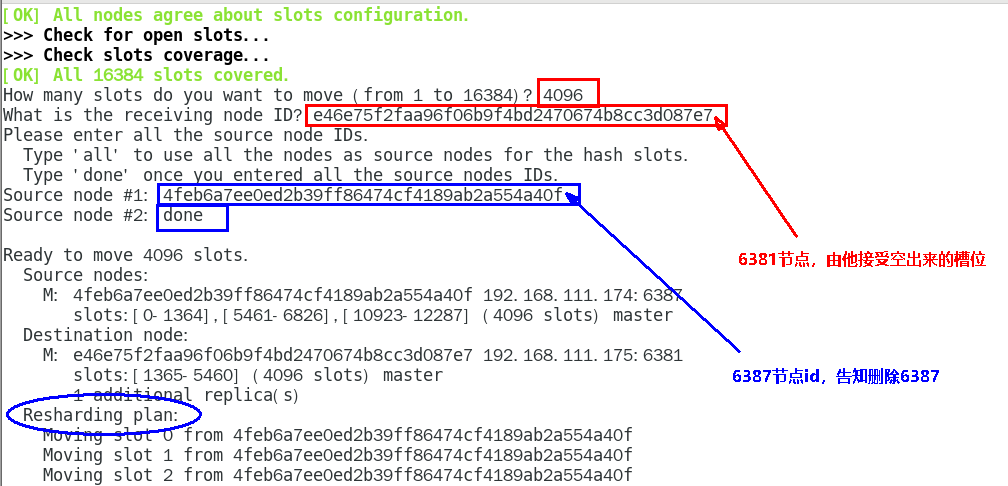
5.重新分派槽号
命令:redis-cli -a 密码 --cluster reshard IP地址:端口号
redis-cli -a 密码 --cluster reshard 192.168.111.175:6381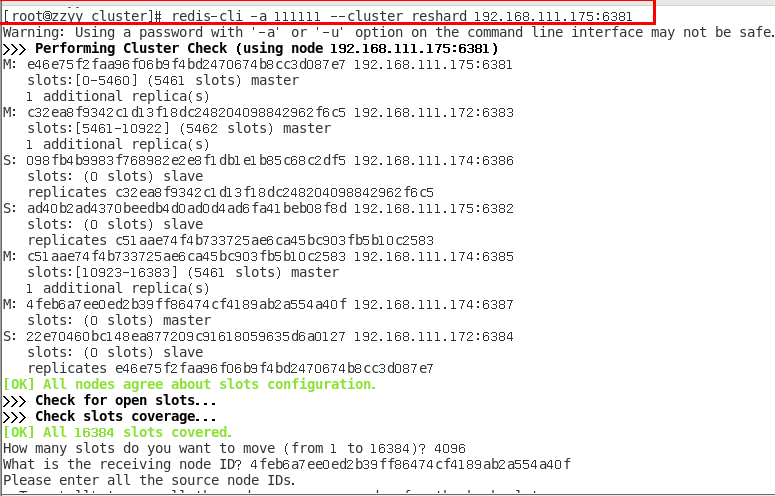
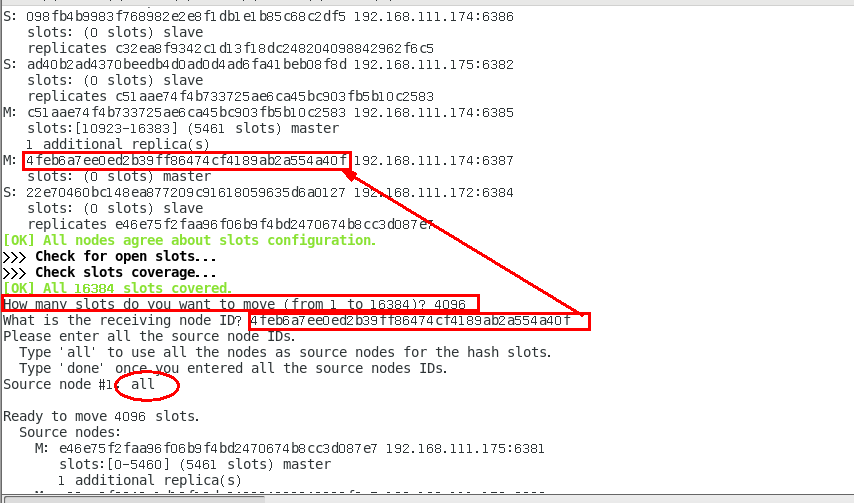
5.再次检查集群状态
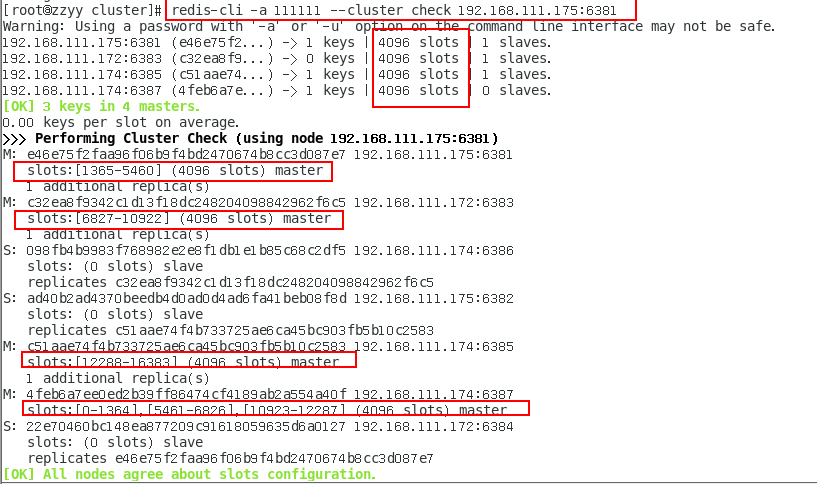
为什么6387是3个新的区间,以前的还是连续?重新分配成本太高,所以前3家各自匀出来一部分,从6381/6383/6385三个旧节点分别匀出1364个坑位给新节点6387
6. 为主节点6387分配从节点6388
命令:redis-cli -a 密码 --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
redis-cli -a 111111 --cluster add-node 192.168.111.174:6388 192.168.111.174:6387 --cluster-slave --cluster-master-id 4feb6a7ee0ed2b39ff86474cf4189ab2a554a40f-------这个是6387的编号,按照自己实际情况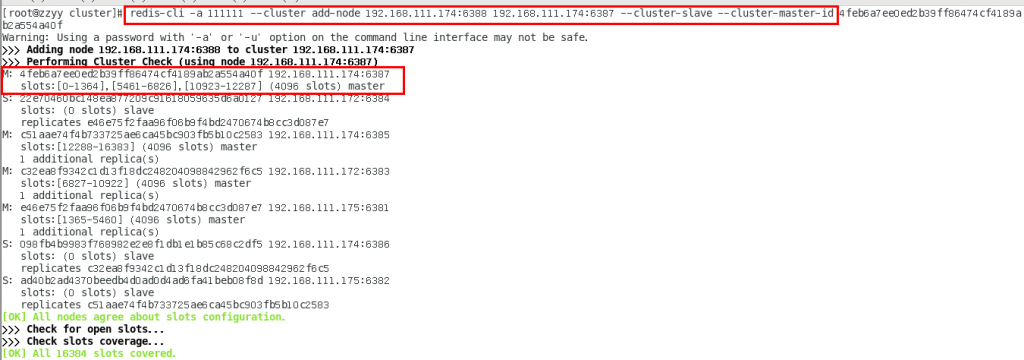

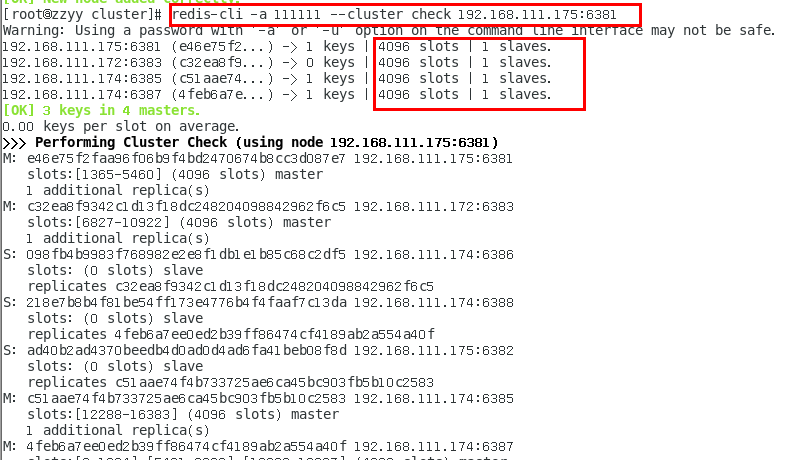
7. 再次检查集群状态
5. 主从缩容
1.检查集群状态,获取6388的节点id
redis-cli -a 密码 --cluster check 192.168.111.174:6388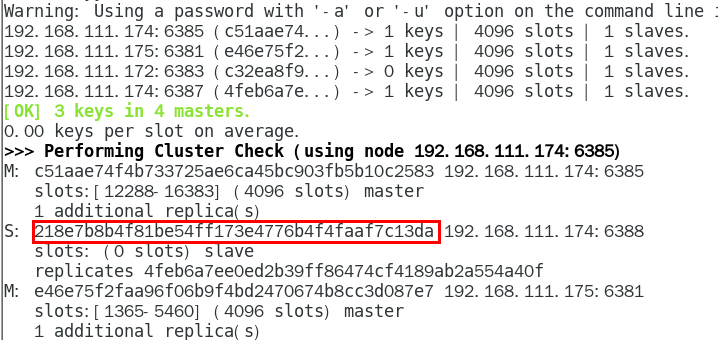
2.从集群中删除6388 节点
命令:redis-cli -a 密码 --cluster del-node ip:从机端口 从机6388节点ID
redis-cli -a 111111 --cluster del-node 192.168.111.174:6388 218e7b8b4f81be54ff173e4776b4f4faaf7c13da
剩余7台redis主机了
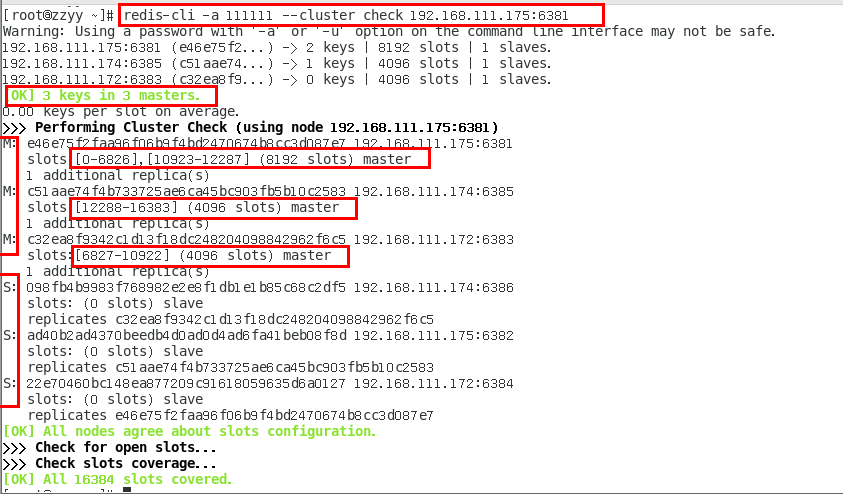
3. 6387 槽位清空,重新分配
redis-cli -a 111111 --cluster reshard 192.168.111.175:6381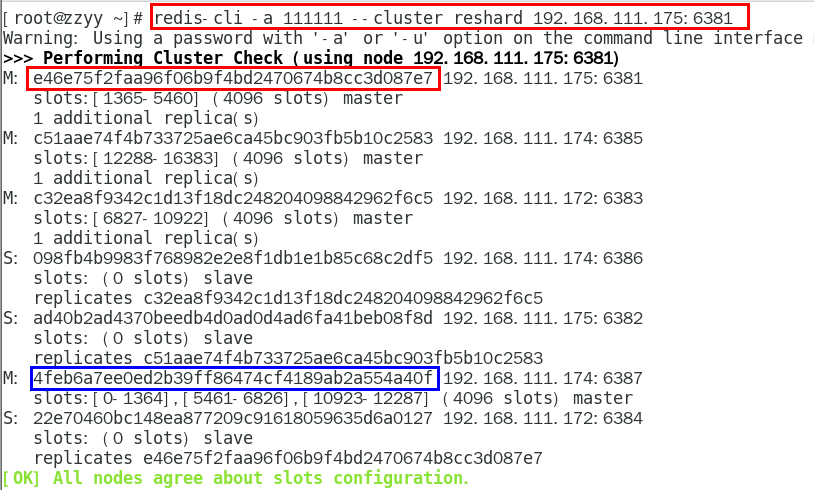
4. 检查集群状态

5.删除7387
redis-cli -a 111111 --cluster del-node 192.168.111.174:6387 4feb6a7ee0ed2b39ff86474cf4189ab2a554a40f
CRC16算法分析
不在同一个槽位下多键操作支持不好,同时占位符登场,可以通过{}来定义同一个组的概念,使key中{}内相同内容的键值对放到一个slot槽位去,对照下图类似k1k2k3都映射为x,自然槽位一样
集群中有16384个哈希槽。每个个key通过CRC16算法对16384取模进行分配放入那个槽,集群的每个节点负责一部分槽位
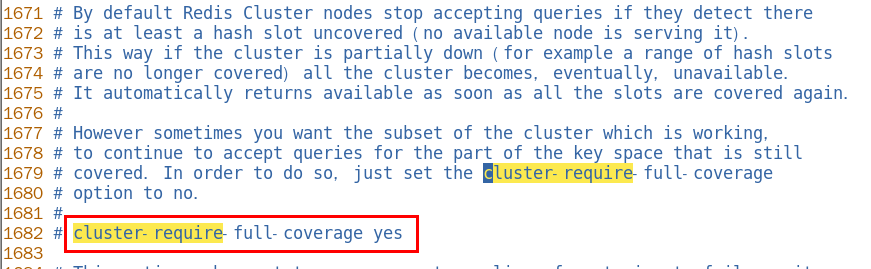
| 默认YES,现在集群架构是3主3从的redis cluster由3个master平分16384个slot,每个master的小集群负责1/3的slot,对应一部分数据。cluster-require-full-coverage: 默认值 yes , 即需要集群完整性,方可对外提供服务 通常情况,如果这3个小集群中,任何一个(1主1从)挂了,你这个集群对外可提供的数据只有2/3了, 整个集群是不完整的, redis 默认在这种情况下,是不会对外提供服务的。 |
| 如果你的诉求是,集群不完整的话也需要对外提供服务,需要将该参数设置为no ,这样的话你挂了的那个小集群是不行了,但是其他的小集群仍然可以对外提供服务。 |
cluster countkeysinslot 槽位数字编号:1槽位占用/0没有占用
cluster keyslot key :key放在那个槽位
11. SpringBoot 集成redis
jedis、lettuce、RedisTemplate三者的关系
- 本地java连接redis常见问题
- bind配置注释掉
- 保护模式为no
- linux防火墙设置
- redisIP地址和密码设置
- 忘记写redis服务端口号和认证密码
创建一个springboot项目,引入依赖
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.2.0</version>
</dependency>
<!--lettuce-->
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>6.3.2.RELEASE</version>
</dependency>测试
@Test
void contextLoads() {
Jedis jedis = new Jedis("192.168.141.91",6379);
jedis.auth("0000");
log.info("redis conn status:{}","连接成功");
log.info("redis ping retvalue:{}",jedis.ping());
jedis.set("k1","jedis");
log.info("k1 value:{}",jedis.get("k1"));
} @Test
void contextLoads1() {
RedisURI uri = RedisURI.builder()
.redis("192.168.141.91")
.withPort(6379)
.withAuthentication("default", "0000")
.build();
//创建客户端
RedisClient redisClient = RedisClient.create(uri);
StatefulRedisConnection conn = redisClient.connect();
//操作命令api
RedisCommands<String,String> commands = conn.sync();
//keys
List<String> list = commands.keys("*");
for(String s : list) {
log.info("key:{}",s);
}
String k1 = commands.get("k1");
log.info("k1 value:{}",k1);//k1 value:jedis
conn.close();
// redisClient.shutdown();
}

RedisTemplate集成
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>application.properties
# 应用服务 WEB 访问端口
server.port=8080
spring.data.redis.database=0
spring.data.redis.host=192.168.141.91
spring.data.redis.port=6379
spring.data.redis.password=0000
spring.data.redis.timeout=5000
spring.data.redis.lettuce.pool.enabled=true
spring.data.redis.lettuce.pool.max-active=20
spring.data.redis.lettuce.pool.max-idle=10
spring.data.redis.lettuce.pool.min-idle=5
@Configuration
public class RedisConfig {
/**
* redis序列化的工具配置类,下面这个请一定开启配置
* 127.0.0.1:6379> keys *
* 1) "ord:102" 序列化过
* 2) "\xac\xed\x00\x05t\x00\aord:102" 野生,没有序列化过
* this.redisTemplate.opsForValue(); //提供了操作string类型的所有方法
* this.redisTemplate.opsForList(); // 提供了操作list类型的所有方法
* this.redisTemplate.opsForSet(); //提供了操作set的所有方法
* this.redisTemplate.opsForHash(); //提供了操作hash表的所有方法
* this.redisTemplate.opsForZSet(); //提供了操作zset的所有方法
* @param lettuceConnectionFactory
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory)
{
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}@Service
@Slf4j
public class OrderService
{
public static final String ORDER_KEY = "order:";
@Resource
private RedisTemplate redisTemplate;
public void addOrder()
{
int keyId = ThreadLocalRandom.current().nextInt(1000)+1;
String orderNo = UUID.randomUUID().toString();
redisTemplate.opsForValue().set(ORDER_KEY+keyId,"京东订单"+ orderNo);
log.info("=====>编号"+keyId+"的订单流水生成:{}",orderNo);
}
public String getOrderById(Integer id)
{
return (String)redisTemplate.opsForValue().get(ORDER_KEY + id);
}
}@RestController
@Slf4j
public class OrderController
{
@Resource
private OrderService orderService;
@RequestMapping(value = "/order/add",method = RequestMethod.POST)
public void addOrder()
{
orderService.addOrder();
}
@RequestMapping(value = "/order/{id}", method = RequestMethod.GET)
public String findUserById(@PathVariable Integer id)
{
return orderService.getOrderById(id);
}
}redis 集群
修改配置文件
spring.redis.password=111111
# 获取失败 最大重定向次数
spring.redis.cluster.max-redirects=3
spring.redis.lettuce.pool.max-active=8
spring.redis.lettuce.pool.max-wait=-1ms
spring.redis.lettuce.pool.max-idle=8
spring.redis.lettuce.pool.min-idle=0
spring.redis.cluster.nodes=192.168.111.175:6381,192.168.111.175:6382,192.168.111.172:6383,192.168.111.172:6384,192.168.111.174:6385,192.168.111.174:6386模拟6381master宕机,从机上位,集群自动感知完成主备切换,6384从机上位成功
spring客户端没有感知到集群变化信息
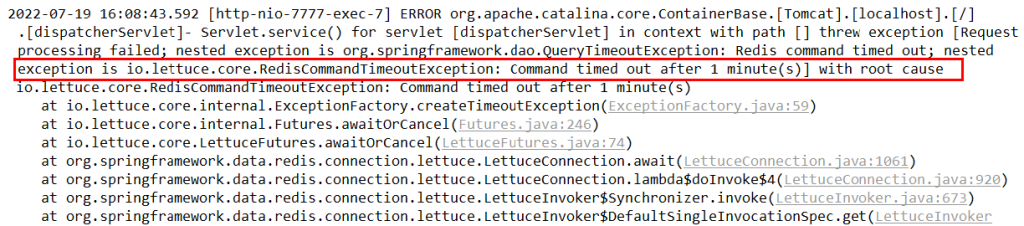

解决方案
spring.redis.password=111111
# 获取失败 最大重定向次数
spring.redis.cluster.max-redirects=3
spring.redis.lettuce.pool.max-active=8
spring.redis.lettuce.pool.max-wait=-1ms
spring.redis.lettuce.pool.max-idle=8
spring.redis.lettuce.pool.min-idle=0
#支持集群拓扑动态感应刷新,自适应拓扑刷新是否使用所有可用的更新,默认false关闭
spring.redis.lettuce.cluster.refresh.adaptive=true
#定时刷新
spring.redis.lettuce.cluster.refresh.period=2000
spring.redis.cluster.nodes=192.168.111.175:6381,192.168.111.175:6382,192.168.111.172:6383,192.168.111.172:6384,192.168.111.174:6385,192.168.111.174:6386测试其他数据类型API
0 条评论